… Because I’m behind the great firewall.
It actually quite surreal being unable to check twitter – I didn’t realize I would miss it so much.
However, I can apparently still blog so will have a post on Tuesday.
… Because I’m behind the great firewall.
It actually quite surreal being unable to check twitter – I didn’t realize I would miss it so much.
However, I can apparently still blog so will have a post on Tuesday.
Over at the Beyond the Commons blog Aaron Wherry has a series of quotes from recent speeches on healthcare by Canadian Prime Minister Stephen Harper in which the one constant keyword is… accountability.
Who can blame him?
Take everyone promising to limit growth to a still unsustainable 6% (gulp) and throw in some dubiously costly projects ($1 billion spent on e-health records in Ontario when an open source solution – VistA – could likely have been implemented at a fraction of the cost) and the obvious question is… what is the country going to do about healthcare costs?
I don’t want to claim that open data can solve the problem. It can’t. There isn’t going to be a single solution. But I think it could help spread best practices, improve customer choice and service as well as possibly yield other potential benefits.
Anyone who’s been around me for the last month knows about my restaurant inspection open data example (which could also yield healthcare savings) but I think we can go bigger. A Federal Government that is serious about accountability in Healthcare needs to build a system where that accountability isn’t just between the provinces and the feds, it needs to be between the Healthcare system and its users; us.
Since the feds usually attach several provisions to their healthcare dollars, the one I’d like to see is an open data provision. One where provinces, and hospitals are required to track and make open a whole set of performance data, in machine readable formats, in a common national standard, that anyone in Canada (or around the world) can download and access.
Some of the data I’d love to see mandated to be tracked and shared, includes:
I can imagine a slew of services and analysis that emerge from these, if nothing than a citizenry that is better informed about the true state of its healthcare system. Even something as simple as being able to check ER wait times at all the hospitals near you, so you can drive to the one where the wait times are shortest. That would be nice.
Of course, if the Prime Minister wants to go beyond accountability and think about how data could directly reduce costs, he might take a look at one initiative launched south of the border.
If he did, he might be persuaded to demand that the provinces share a set of anonymized patient records to see if academics or others in the country might be able to build better models for how we should manage healthcare costs. In January of this year I witnessed the launch of the $3 million dollar Heritage Health Prize at the O’Reilly Strata Conference in San Diego. It is a stunningly ambitious, but realistic effort. As the press release notes:
Contestants in the challenge will be provided with a data set consisting of the de-identified medical records of 100,000 patients from the 2008 calendar year. Contestants will then be required to create a predictive algorithm to predict who was hospitalized during the 2009 calendar year. HPN will award the $3 million prize(more than twice what is paid for the Nobel Prize in medicine) to the first participant or team that passes the required level of predictive accuracy. In addition, there will be milestone prizes along the way, which will be awarded to teams leading the competition at various points in time.
In essence Heritage Health is doing to patient management what Netflix (through the $1M Netflix prize) did to movie selections. It’s crowdsourcing the problem to get better results.
The problem is, any algorithm developed by the winners of the Heritage Health Prize will belong to… Heritage Health. This means the benefits of this innovation cannot benefit Canadians (nor anyone else). So why not launch a prize of our own. We have more data, I suspect our data is better (not limited to a single state) and we could place the winning algorithm in the public domain so that it can benefit all of humanity. If Canadian data helped find efficiencies that lowered healthcare costs and improved healthcare outcomes for everyone in the world… it could be the biggest contribution to global healthcare by Canada since Federick Banting discovered insulin and rescued diabetics everywhere.
Of course, open data, and sharing (even anonymized) patient data would be a radical experiment for government, something new, bold and different. But 6% growth is itself unsustainable and Canadians need to see that their government can do something bold, new and innovative. These initiatives would fit the bill.
This is truly, truly fantastic. If you haven’t already read this stunning story from the Guardian: How a big US bank laundered billions from Mexico’s murderous drug gangs. This is, in essence a chronicle how the dark and sordid side of banking and about how one US bank – Wachovia – essentially allowed Mexican drug cartels to launder a whopping $378B.
But this interestingly, is just the tip of the iceberg. It turns out that Mexican money may have been the only thing holding the US financial system together. Check out the following and the last paragraph especially (I’ve bolded it, it is so stunning):
More shocking, and more important, the bank was sanctioned for failing to apply the proper anti-laundering strictures to the transfer of $378.4bn – a sum equivalent to one-third of Mexico’s gross national product – into dollar accounts from so-called casas de cambio (CDCs) in Mexico, currency exchange houses with which the bank did business.
“Wachovia’s blatant disregard for our banking laws gave international cocaine cartels a virtual carte blanche to finance their operations,” said Jeffrey Sloman, the federal prosecutor. Yet the total fine was less than 2% of the bank’s $12.3bn profit for 2009. On 24 March 2010, Wells Fargo stock traded at $30.86 – up 1% on the week of the court settlement.
The conclusion to the case was only the tip of an iceberg, demonstrating the role of the “legal” banking sector in swilling hundreds of billions of dollars – the blood money from the murderous drug trade in Mexico and other places in the world – around their global operations, now bailed out by the taxpayer.
At the height of the 2008 banking crisis, Antonio Maria Costa, then head of the United Nations office on drugs and crime, said he had evidence to suggest the proceeds from drugs and crime were “the only liquid investment capital” available to banks on the brink of collapse. “Inter-bank loans were funded by money that originated from the drugs trade,” he said. “There were signs that some banks were rescued that way.”
But the more interesting part of the story, that picks up on the above quote by Antonio Maria Costa, lies deeper in the story:
“In April and May 2007, Wachovia – as a result of increasing interest and pressure from the US attorney’s office – began to close its relationship with some of the casas de cambio.”
and, a paragraph later…
“In July 2007, all of Wachovia’s remaining 10 Mexican casa de cambio clients operating through London suddenly stopped doing so.”
In other words from April through July, with increasing intensity, Wachovia got out of the drug money laundering business. Of course, this just also happens to be at the exact same time that the liquidity crisis starts hitting US banks prompting “The Bank Run We Knew So Little About.”
This is not to say that the financial crises was caused by drug money – it wasn’t. All those crazy mortgages and masses of consumer debt created a house of cards that was teetering away. But it could be that the sudden end to access of vast billions of Latin America drug money did tip the system over the edge.
I say this because here in Canada we have a government that not only does not believe in harm reduction as an effective way to deal with the drug problem, but it intends to pursue a prison focused US style approach to crime that even the most ardent US conservatives are calling a failure. And why does this matter? I mention the above stories because it is worth noting the size, scope and complexity of problem with face. This is a structural, systemic problem, not something that is going to be solved by throwing an additional 1,000 or even 100,000 people in jail. $378B. Through one bank. One third of Mexico’s GDP. And that’s all just pure profit. That’s probably 80 times more than we spend on fighting the war on drugs every year. Through one bank.
And, as the US authorities appear to have demonstrated it may be that the only thing more expensive than losing the war on drugs is winning a major battle – as apparently that can throw the entire global financial system into disarray. So if we think that upping the amount we spend on this war by $1B or even $10B is going to make a lick of difference, we’ve got another thing coming. But I suppose in the mean time, it will secure a few votes.
Even sometimes my home town of Vancouver gets it wrong.
Reading Chad Skelton’s blog (which I frequently regularly and recommend to my fellow Vancouverites) I was reminded of the great work he did creating an interactive visualization of the city’s parking tickets as part of a series around parking in Vancouver. Indeed, it is worth noting that the entire series was powered by data supplied by the city. Sadly, it just wasn’t (and still isn’t) open data. Quite the opposite, it was data that was wrestled, with enormous difficulty, via an FOI (ATIP) request.
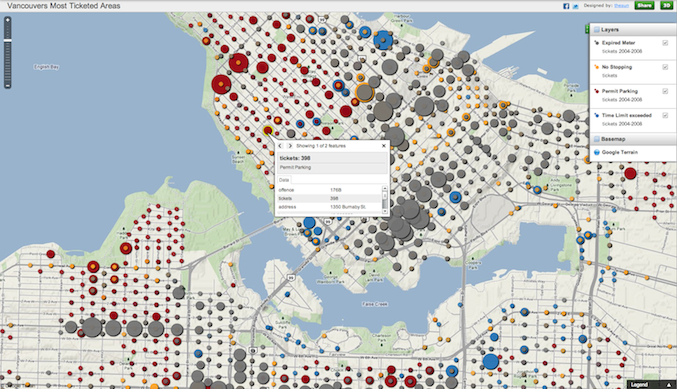
In the same blog post Chad recounts how he struggled to get the parking data from the city:
Indeed, the last major FOI request I made to the city was for its parking-ticket data. I had to fight the city tooth and nail to get them to cough up the information in the format I wanted it in (for months their FOI coordinator claimed, falsely, that she couldn’t provide the records in spreadsheet format). Then, when the parking ticket series finally ran, I got an email from the head of parking enforcement. He was wondering how he could get reprints of the series — he thought it was so good he wanted to hand it out to new parking enforcement officers during their training.
What is really frustrating about this paragraph is the last sentence. Obviously the people who find the most value in this analysis and tool are the city staff who manage parking infractions. So here is someone who, for free(!), provides an analysis and some stories that they now use to train new officers and he had to fight to get the data. The city would have been poorer without Chad’s story and analysis. And yet it fought him. Worse, an important player in the civic space (and an open data ally) feels frustrated by the city.
There are of course, other uses I could imagine for this data. I could imagine the data embedded into an application (ideally one like Washington DC’s Park IT DC – which let’s you find parking meters on a map, identify if they are available or not, and see local car crime rates for the area) so that you can access the risk of getting a ticket if you choose not to pay. This feels like the worse case scenario for the city, and frankly, it doesn’t feel that bad and would probably not affect people’s behaviour that much. But there may be other important uses of this data – it may correlate in some interestingly and unpredictably against other events – connections that if made and shared, might actually allow the city to leverage its enforcement officers more efficiently and effectively.
Of course, we won’t know what those could be, since the data isn’t shared, but it is the kind of thing Vancouver should be doing, given the existence of its open data portal. But all government’s should take note. There is a cost to not sharing data. Lost opportunities, lost insights and value, lost allies and networks of people interested in contributing to your success. It’s all our loss.
Yesterday I was reminded by the fact that I have great friends – friends who are far better to me than I deserve. You see, yesterday was my birthday and I was overwhelmed with the number of well wishers who sent me a little note. I’m so, so lucky – something I should never forget.
It was also an illustrative guide to technology adoption and technology is and isn’t impacting my life.
I was struck by the way people got in touch with me. I’m a heavy twitter user and so I don’t spend a lot of time on facebook but yesterday was a huge reminder of how much in the minority I am. While I received maybe 10 mentions or DMs wishing me a happy birthday via twitter (all deeply appreciated) I received somewhere around 100 wall postings and/or facebook messages. Good old email came in at around 15-20 messages. Facebook is simply just big. Huge even. I know that on an intellectual level, but it is great to have these visceral reminders every once in a while. They hit home much harder.
Of course, the results are not a perfect metric of adoption. One thing facebook has going for it that email and twitter don’t is it reminds you of your friends birthdays on its landing page. This is just plain smart of facebook’s part. But it is also interesting in that, knowing this face had no impact on how happy or grateful I was to get messages from people. The fact that technology reminded people – and so they weren’t simply remembering on their own – didn’t matter a lick in how happy I was to hear from them. Indeed, it was wonderful to hear from people – such as old high school friends – I haven’t seen or heard of in ages.
All of this is to say, I continue to read how social media sites and social networks specifically are creating more superficial connections and reducing the quality or intensity of who is a “friend.” My birthday was a great reminder of how ridiculous this talk is. My close friends still reached out, and I got to spend a great day on the weekend with a number of them. Facebook has not displaced them. What it has done however is kept me connected with people who can’t always be close to me, either because of the constraints of geography, or because the evolution of time. Ultimately, these technologies don’t create binary choices between having close intimate friends or lots of weak ties, they are complimentary. My close friends who move away can stay connected to me, and those with whom I form “loose” ties, migrate into my strong ties.
In both cases – for those I get to see frequently and those I don’t – I’m grateful to have them in my life, and that Facebook, twitter and email makes this easier has frankly, made my life richer.
A few weeks ago I finished “What Technology Wants” by Kevin Kelly. For those unfamiliar with Kelly (as I was) he was one of the co-founders of Wired magazine and sits on the board of the Long Now Foundation.
What Technology Wants is a fascinating read – both attracting and repulsing me on several occasions. Often I find book reading to be a fairly binary experience – either I already (explicitly or intuitively) broadly agree with the thesis and the book is an exercise in validation and greater evidence, or I disagree, and the book pushes me to re-evaluate assumptions I have. More rare is a book which does both at the same time.
For example, Kelly’s breakdown of the universe as a series of systems for moving around information so completely resonated with me. From DNA, to language, to written word, our world keeps getting filled with systems the transmit, share and remix more information faster. The way Kelly paints this universe is fascinating and thought provoking. In contrast, his determinist view of technology, that we are pre-ordained to make the next discovery and that, from a technological point of view, our history is already written and is just waiting to unwind, ran counter to so many of my values (a strong believer in free-will). It was as if the tech-tree from a game like Civilization actually got it all right – that technology had to be discovered in a preset order and that if we rewound the clock of history, it would (more or less) this aspect of it would play out the same.

The tech tree is civilization always bothered me on a basic level – it challenged the notion that someone smart enough, with enough vision and imagination could have in a parallel universe, created a completely different technology tree in our history. I mean, Leonardo De Vinci drafted plans for helicopters, guns and tanks (among other things) in the 14th century? And yet, Kelly’s case is so compelling and with the simplest of arguments: No inventor ever sits around unworried that someone else is going to make the same discovery – quite the opposite, inventors know that a parallel discovery is inevitable, just a matter of time, and usually not that much time.
Indeed, Kelly convinces me that the era of the unique idea, or the singular discovery may be over, in fact the whole thing was just an illusion created by the limits of time, space and capacity. Previously, it took time for ideas to spread, so they could appear to come from a single source, but in a world of instant communication, we increasingly see that ideas spring up simultaneously everywhere – an interest point given the arguments over patents and copyright.
But what I’d really like to read is a feminist critique of What Technology Wants (if someone knows of one, please post it or send it to me). It’s not that I think that Kelly is sexist (there is nothing that suggests this is the case) it is just that the book reads like much of what comes out of the technology space – which sadly – tends to be dominated by men. Indeed, looking at the end of the book, Kelly thanks 49 thinkers and authors who took time to help him enhance his thesis, and the list is impressive including names such as Richard Dawkins, Chris Anderson, David Brin, and Paul Hawken. But I couldn’t help but notice only 2 of the 49 were obviously women (there may be, tops 4 women, who made the list). What Technology Wants is a great read, and I think, for me, the experience will be richer once I see how some other perspectives wrap their heads around its ideas.
Evolving thought:
One of the large challenges of the 21st century is going to be reconciling our increasingly networked world with traditional notions of individualism.
The more I look at a networked world – not in some geopolitical sense but on a day to day experience for everyone – the more it appears that many of the core to elements of liberal individualism are going to be challenged. Authorship is a great example of this dynamic playing out – yes Wikipedia makes it impossible to identify who an author is – but even tweets, and blogs and all forms of digital medium confuse who is the original author of a work. More over, we may no longer live in a world of unique individual thought. As Kevin Kelly so remarkably documents in What Technology Wants by looking at patent submissions and scientific papers, it is increasingly apparent that technologies are being simultaneously discovered everywhere, the notion of attributing something to an individual may be at best difficult, at worst impossibly random.
And of course networked systems disproportionately reward hubs. Hubs in a network attract more traffic (ideas/money/anything) and therefor may appear to many others in the network as the source of these ideas as they are shared out. I for example get to hear more about open data, or technology and government, then many other people, as a result my thinking gets to be pushed further and faster allowing me to in turn share more ideas that are of interest and attract still more connections. I benefit not simply from inherent individual abilities, but from the structure of, and my location in, a network.
Of course, socialist collectivism is going to be challenged as well in some different way but I think that may be less traumatic for our political systems the a direct challenge to individualism – something many centrist and right leaning parties may struggle with.
This is all still half formed but mental note for myself. More thinking/research on this needed. Open to ideas, articles, etc…
This week at the Mesh conference in Toronto (where I’ll be talking Open Data) the always thoughtful Jesse Brown, of TVO’s Search Engine will be running a session title How to Unsuck Canada’s Internet.
As part of the lead up to the session he asked me if I could write him a sentence or two about my thoughts on how to unsuck our internet. In his words:
The idea is to take a practical approach to fixing Canada's lousy Internet (policies/infrastructure/open data/culture- interpret the suck as you will).
So my first thought is that we should prevent anyone who owns any telecommunications infrastructure from owning content. Period. Delivery mechanisms should compete with delivery mechanisms and content should compete with content. But don’t let them mix, cause it screws up all the incentives.
A second thought would be to allocate the freed up broadcast spectrum to new internet providers (which is really what all the cell phone providers are about to become anyways). I’m actually deeply confident that we may be 5 years away from this problem becoming moot in the main urban areas. Once our internet access is freed from cables and the last mile, then all bets are off. That won’t help rural areas, but it may end up transforming urban access and costs. Just like cities clustered around seaports and key places nodes along trade networks, cities (and workers) will cluster around better telecommunication access.
But the longer thought comes from some reflections over the timely recent release of OpenMedia.ca/CIPPIC’s second submission to the CRTC’s proceedings on usage-based billing (UBB) which I think is actually fairly aligned with the piece I wrote back in February on titled Why the CRTC was right about User Based Billing (please read the piece and the comments below before freaking out).
Here, I think our goal shouldn’t be punitive (that will only encourage the telco’s to do “just enough” to comply. What we need to do is get the incentives right (which is, again, why they shouldn’t be allowed to own content, but I digress).
An important part of getting the incentives right is understanding what the actual constraints on internet access. One of the main problems is that people often get confused about what is scarce and what is abundant when talking about the internet. I think what everyone realizes is that content is abundant. There are probably over a trillion websites out there, billions of videos and god knows what else. There is no scarcity there.
This is why any description of access that uses an image like the one below will, in my mind, fail.
Charging per byte shouldn’t be permitted if the pipe has infinite capacity (or at least it wouldn’t make sense in a truly competitive market). What should happen is that companies would be able to charge the cost of the infrastructure plus a reasonable rate of return.
But while the pipe may have infinite capacity over time, at any given moment it does not. The issue isn’t about how many bytes you consume, it’s about the capacity to deliver those bytes in a given moment when you have lots of competing users. This is why it isn’t the “where the data is coming from/going to” that matters, but rather how much of it is in the pipe at a given moment. What matters is not the cable, but the it’s cross section.

A cable that is empty or only at 40% capacity should deliver rip-roaring internet to anyone who wants it. My understanding is that the problem is when the cable is at 100% or more capacity. Then users start crowding each other out and performance (for everyone) suffers.


Indeed this is where the OpenMeida/CIPPIC document left me confused. On the one hand they correctly argue that the internet’s content is not a limited resource (such as natural gas). But they seem to be arguing that the network capacity is not a finite resource (sections 21 and 22) while at the same time accepting that there may be constraints on capacity during peak hours (sections 27 and 30 where they seem to accept that off peak users should not be subsidizing peak time users and again in the conclusion where they state “As noted in far greater detail above, ISP provisioning costs are driven primarily by peak period usage.” If you have peak period usage then, by definition, you have scarcity). The last two points seem to be in conflict. The network capacity cannot be both infinite and constrained during peak hours? Can it?
Now, it may be that there is more network capacity in Canada then there is demand – even at peak times – at which point, any modicum of sympathy I might have felt for the telcos disappears immediately. However, if there is a peak consumption period that does stress the network’s capacity, I’d be relatively comfortable adopting a pricing mechanism that allocates the “scarce” amount of broadband pie. Maybe there are users – especially many BitTorrenters – whose activities are not time sensitive. Having a system in place that encourages them to bittorrent during off-peak hours would create a network that was better utilized.
So the OpenMedia piece seems to be open to the idea of peak usage pricing (which was what I was getting at in my UBB piece) so I think we are actually aligned (which is good since I like the people at OpenMedia.ca).
The question is, does this create the right incentives for the telco’s to invest more in capacity? My hope would be yes, that competition would cause users to migrate to networks that provided high speeds and competitive low and/or peak usage time fees. But I’m open to the possibility that it wouldn’t. It’s a complicated problem and I don’t pretend to think that I’ve solved it in one blog post. Just trying to work it though in my head.
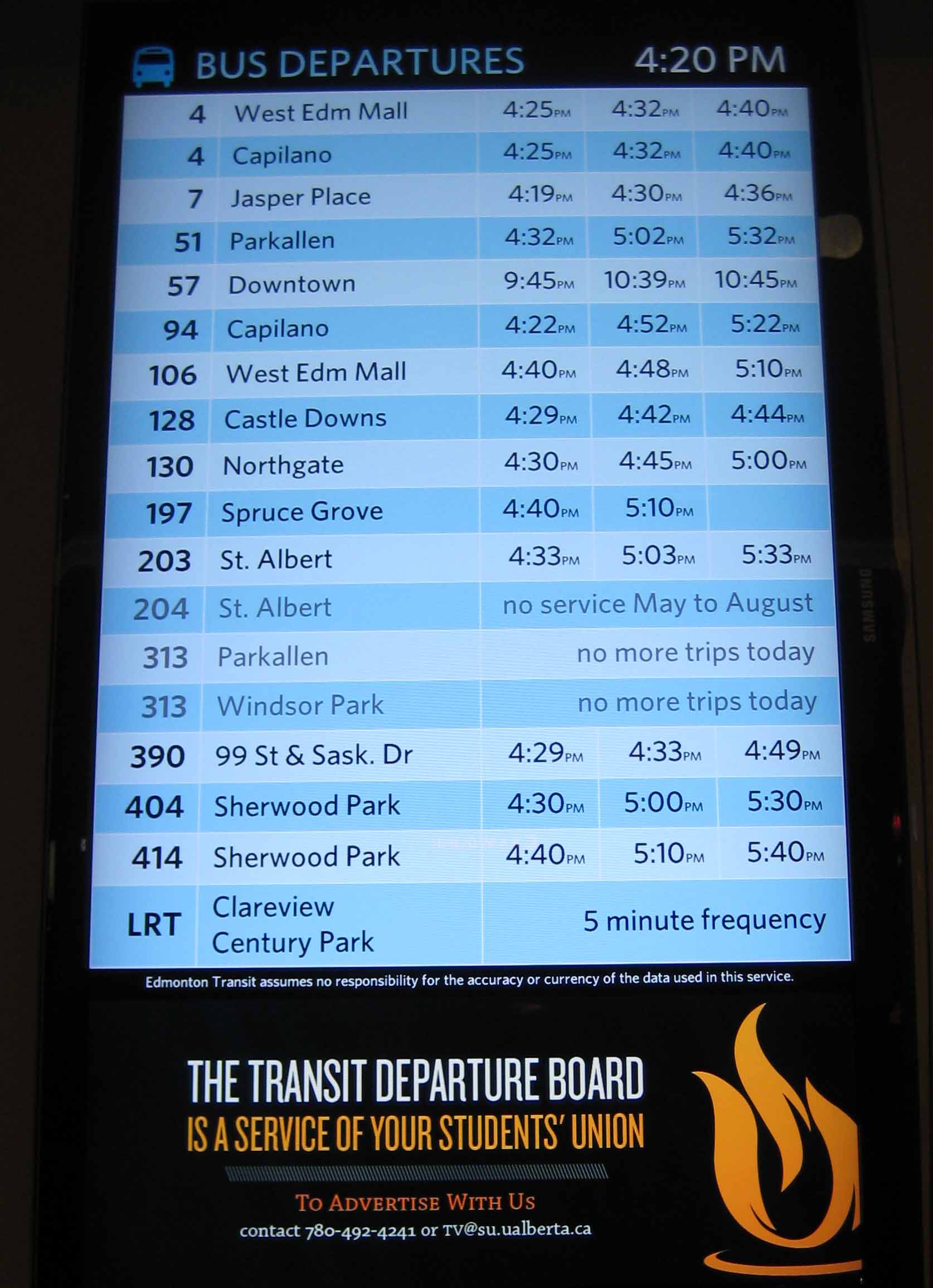
Yesterday, Gerry T shared a photo he snapped at the University of Alberta in Edmonton of a “departure board” in the university’s Student Union building that uses open transportation data from the city’s website.
Essentially the display board is composed of a simply application, displayed over a large flat screen TV turned vertically.
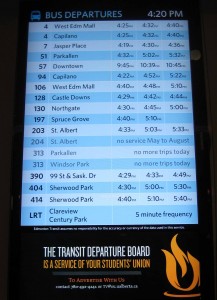 It’s exactly the kind of thing that I imagine University Students in many cities around the world wish they had – especially if you are on a campus that is cold and/or wet. Wouldn’t it be nice to wait inside that warm student union building rather than at the bus stop?
It’s exactly the kind of thing that I imagine University Students in many cities around the world wish they had – especially if you are on a campus that is cold and/or wet. Wouldn’t it be nice to wait inside that warm student union building rather than at the bus stop?
Of course in Boston they’ve gone further than just providing the schedule online. They provide real-time data on bus locations which some students and engineers have used to create $350 LED signs in coffee houses to let users know when the next bus is coming.
It’s the kind of simple innovations you wish you’d see in more places: government’s letting people help themselves at making their lives a little easier. Yes, this isn’t changing the world, but its a start, and an example of what more could happen.
Mostly it’s nice to see innovators in Canada like playing with the technology. Hopefully governments will catch up and let the even bigger ideas students around the country have be more than just visions in their heads.
Not sure who at the University created this, but nice work.
Yesterday, New York City released its “Road Map for the Digital City: Achieving New York City’s Digital Future.” For those who missed the announcement, especially those concerned about the digital economy, the future of government and citizen services, the document is definitely worth downloading and scanning.
At the heart of the document sits a road map which I’ve ripped from the executive summary and pasted below.What makes me particularly interested in it is how the Open Government section is not uniquely driven by the desire for transparency but with the goal of spurring innovation and increasing access to services. Of course, the devil is in the details but I’m increasingly convinced that open initiatives will be more successful when the government of the day has some specific policy objectives (beyond just transparency) it wishes to drive home, with open data as part of the mix (more on this in a post coming soon).
As such, “government as platform” works best when the government also builds atop the platform. It itself must be a consumer and stakeholder. This is why section 3 is so important and interesting. Essentially section 2 and 3 have parts that are strikingly similar, its just that section 2 outlines the platform and lays out that the government hopes others will build on top of it whereas parts of section 3 outline what the government intends to build atop of it. Of course section 3 goes further and talks as well about gathering information and data from the public which is the big thing in the Gov 2.0 space that many governments have not gotten around to doing effectively – so this will be worth watching more closely. All of this is great news and exactly what governments should be thinking about.
It is great when a big city comes out with a document like this because while New York is not the first to be thinking these ideas, but its profile means that others will start devoting resources to pursue these ideas more aggressively.
Exciting times.
1. Access
The City of New York ensures that all New Yorkers can access the Internet and take advan- tage of public training sessions to use it effectively. It will support more vendor choices to New Yorkers, and introduce Wi-Fi in more public areas.
- Connect high needs individuals through federally funded nyc Connected initiatives
- Launch outreach and education efforts to increase broadband Internet adoption
- Support more broadband choices citywide
- Introduce Wi-Fi in more public spaces, including parks
2. Open Government
By unlocking important public information and supporting policies of Open Government, New York City will further expand access to services, enable innovation that improves the lives of New Yorkers, and increase transparency and efficiency.
- Develop nyc Platform, an Open Government framework featuring APIs for City data
- Launch a central hub for engaging and cultivating feedback from the developer community
- Introduce visualization tools that make data more accessible to the public
- Launch App Wishlists to support a needs-based ecosystem of innovation
- Launch an official New York City Apps hub
3. Engagement
The City will improve digital tools including nyc.gov and 311 online to streamline service and enable citizen-centric, collaborative government. It will expand social media engagement, implement new internal coordination measures, and continue to solicit community input in the following ways:
- Relaunch nyc.gov to make the City’s website more usable, accessible, and intuitive
- Expand 311 Online through smartphone apps, Twitter and live chat
- Implement a custom bit.ly url redirection service on nyc.gov to encourage sharing and transparency
- Launch official Facebook presence to engage New Yorkers and customize experience
- Launch @nycgov, a central Twitter account and one-stop shop of crucial news and services
- Launch a New York City Tumblr vertical, featuring content and commentary on City stories
- Launch a Foursquare badge that encourages use of New York City’s free public places
- Integrate crowdsourcing tools for emergency situations
- Introduce digital Citizen Toolkits for engaging with New York City government online
- Introduce smart, a team of the City’s social media leaders
- Host New York City’s first hackathon: Reinventing nyc.gov
- Launch an ongoing listening sessions across the five boroughs to encourage input
4. Industry
New York City government, led by the New York City Economic Development Corporation, will continue to support a vibrant digital media sector through a wide array of programs, including workforce development, the establishment of a new engineering institution, and a more stream- lined path to do business.
- Expand workforce development programs to support growth and diversity in the digital sector
- Support technology startup infrastructure needs
- Continue to recruit more engineering talent and teams to New York City
- Promote and celebrate nyc’s digital sector through events and awards
- Pursue a new .nyc top-level domain, led by DOITT


{kind=link}