As many readers are likely aware two weeks ago The Journal News, a newspaper just outside of New York city, published a map showing the addresses and names of handgun owners in Westchester and Rockland counties. The map, which was part of a story responding to the tragic shooting in Newtown, Connecticut, was constructed with data the paper acquired through Freedom of Information requests. Since their publication the story has generated enormous public interest, including a tremendous amount of anger from gun owners and supporters. The newspaper and its staff have received death threats, had their home addresses published and details of where their kids attend school published. Today the newspapers headquarters are guarded by… armed guards.
While there is a temptation to talk about this even in terms of open data, I don’t think this is a debate about open data. This is a debate about privacy and policy.
Let me clarify.
There is lots of information governments collect about people – the vast majority of which is not, and should not be available. As both an open data advocate and a gov 2.0 advocate I’m strongly interested in ensuring that – around any given data set – peoples sense of privacy is preserved. There are of course interests that benefit from information being made inaccessible, just as there are interests that benefit from it being made accessible, but when it comes to individually identifying pieces of information, I prefer to be cautious.
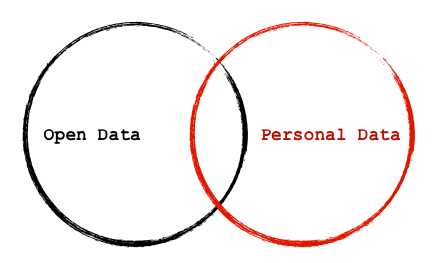
So, from my perspective, it is critical that this debate not get sloppy. This is not about open data. It is about personable identifiable data – and what governments should and should not do with it. Obviously “open” and “personal identifiable” data can overlap, but they are not the same. A great deal of open data has nothing to do with individuals. However, if we allow the two to become synonymous… well… expect a backlash against open data. No one ever gave anyone a blank check to make any and everything open. I don’t expect my personal healthcare or student record to be downloadable by anyone – I suspect you don’t either.
This is why – when I advise governments – I try to focus on data that is the least contentious (e.g. not even at risk of being personally identifying) since this gives public servants, politicians and the public some time to build knowledge and capacity around understand the issues.
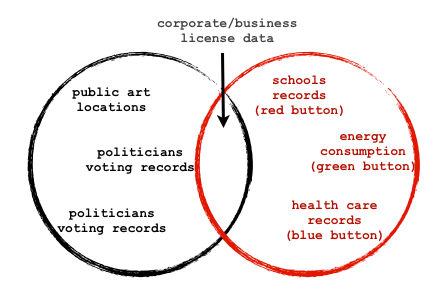
This is not to say that no personalbly identifiable data should be made available – the question is, to what end? And the question matters. I suspect privacy played a big part if the outcry and reaction to the Journal’s gun map. But I suspect that for many – particularly strong pro-gun advocates – there was a recognition that this data was being used as a device (of VERY unclear efficacy) to accelerate public support for stricter gun laws. So they object not just to the issue of privacy, but to the usage.
In the case of guns, I don’t know what the right answer is. But here is an example I feel more confident about. Personally I (and many others) believe businesses license data should be open, including personal identifiable data. But again, these are issues that need to be hammered out, debated and the public given choices. This is not where the open data discussion needs to start, and this is certainly not how it should be defined in the public, as it is much, much more that that and includes touches many issues that are far, far less contentious. But we need to be building the capacity – in the public, among politicians and among public servants – to have these conversations, because disclosure, or the lack thereof, will increasingly be a political and policy choice.
And many of these questions will be tricky. I also believe data should be made available in aggregate. While I understand there are risks I believe researchers should be allowed to use large data sets to try to find out how age or other factors might effective a terrible medical condition, or to gain insights into how graduation rates of at risk groups might be improved. These are big benefits that are – again, for me, worth the risk. But they will of course need to constantly be weighed and debated. What personal data should also be allowed to become open data, under what circumstances and to whose benefit… these are big questions.
So, if you are an open data advocates out there – please don’t let people confuse Open Data with Personal Data. The two can and almost certainly will overlap at times. But that does not make them the same thing. If these two terms become synonymous in the public’s mind in ANY way, it could take years to recover. So educate yourself on privacy issues, and be sure to educate the people you work with. But above all, help them get ready for these debates. More are coming.
Some additional Thoughts
Of course, when it comes to data, if you are really worried about personally identifiable stuff, there is a lot more to fear that isn’t maintained by governments. The world of free and purchasable data contains a lot of goodies (think maps, stock prices, etc…) but there is also plenty of overlap with personal data as well.
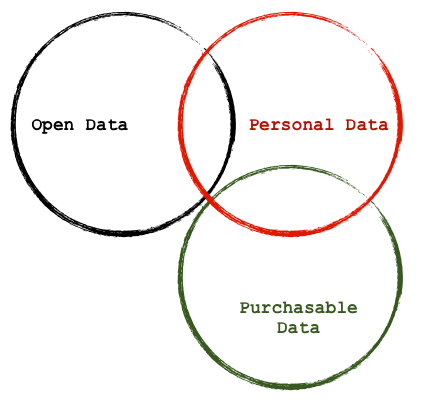
Indeed, much of the retaliatory data about the employees of The Journal News was data that was personally identifiable and readily available. A simple look at who I follow on twitter would likely reveal a fair bit about my social graph to anyone. And this isn’t even the juicy stuff. One wonders how many people realize just how much about them can be purchased. Indeed accessing some information has become so common place people don’t even think about it anymore: my understanding is that almost anyone can get a copy of your credit score, right?
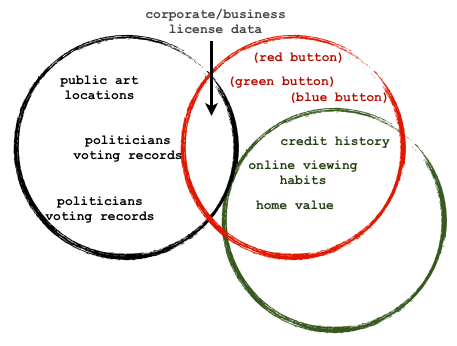
That siad, I recognize the difference between data the state forces you to disclose (gun ownership) and that which you “voluntarily” submit and cede control over so as to take part in a service (facebook friends). I don’t always like the latter, but I recognize it is different from the government – it is one thing to have a monopoly on violence it is another to have a terrible EULA. That said, I suspect that many people would be disturbed if they saw exactly how many people were tracking all of the things they do online. Mozilla’s Collusion project is a fun – if ultimately fruitless – tool for getting a sense of this. It is worth doing for a day just to see who is watching what you watch and do online.
I share all this not because I want to scare anyone – indeed I suspect these additional notes are old hat to anyone still reading, but recognize how complex the public’s relationship with data is. And as much as it will upset my privacy advocacy friends to hear me say this: my sense is that public is actually still quite comfortable with vast amounts of data about them being collected (Facebook seems to be able to do whatever it wants with almost no impact on usage). Where people get finicky is around how that data gets used. Apparently, be sold to more effectively doesn’t bother them all that much (although I wish some algorithm could figure out that I’ve already bought a fitbit so there ads need no longer follow me all over the web). However, try to use it to take away their guns… and some of them will get very angry. Somewhere in there a line has been drawn. It has all the makings of an epic public policy and corporate policy nightmare.

Thank you David for posting this. While it is not directly an open data issue it does bring up an ethical question on privacy and linked data. Open Raleigh, which I manage, is using this event as a jumping off point for discussing our privacy policy. We want to err on the side of the citizen and not disclose personally identifiable information.
Thank you David for posting this. While it is not directly an open data issue it does bring up an ethical question on privacy and linked data. Open Raleigh, which I manage, is using this event as a jumping off point for discussing our privacy policy. We want to err on the side of the citizen and not disclose personally identifiable information.
Pingback: The Journal News Gun Map: Open vs. Personal Data | Open Government Daily | Scoop.it
Pingback: The Journal News Gun Map: Open vs. Personal Data | Open Knowledge | Scoop.it
Pingback: The Journal News Gun Map: Open vs. Personal Data | Municipal Open Data | Scoop.it
I think you haves pretty significant typo; “So if you are an open data advocate … please do [sic] let people confuse [Open | Personal] Data”
Thanks for the post!
Fixed! Thank you!
David – first, thanks for the walk-through on the ideas expressed. Nicely put! Second, I wonder where in the conversation here you see the sharing of that slice of purchasable “anonymous” data sold to other businesses who de-anonymize it using related information from other sources. Those other businesses in turn sell their data to other users for clearly unintentional consequences (marketing, surveillance, etc)
Do you think that protections can be improved to prevent this use? It appears to be a work-around for people who want to sell information they’ve promised to keep to themselves.
Okay, complicated issue that I guarantee I won’t handle all the nuances of in this response, but here is where my thinking is at.
a) there are some data sets that are just plain private and only individuals should have the right to share them (in personally identifiable ways) – specifically I’m thinking health and education records and the sort.
b) that said, I don’t think it is possible to put the data genie back in the bottle. Even with health records – I’m suspecting my credit card company, of even some browser cookies – can probably discern if I get cancer by looking at my spending or webpage viewing patterns.
c) so I’m thinking there are probably so core data sets we want to protect and then we will need to legislate against use – e.g. it will be illegal to de-anonymize or to reconstruct my healthcare records, or to make decisions based on inferences of what my health records might be.
Of course “c” will create a whole new set of problems, so there is not going to be any simple solutions. In addition, people’s values and notions of privacy may change. What we believe should be private may evolve – certainly these norms and perspectives have shifted in the last 50, to say nothing of the last 150 or 400 years, so we should be careful about cementing in a notion too firmly and prevent it from evolving in either direction.
I think that many open data folks know that when it come to do some advocacy, the first thing to say is that open data concerns “non personal” data since privacy is frequently one of the first concern.
However, it is already frequent to have personal data available thru “open data”: political donations is a great example. You also have some crime and sex offenders databases (does the fact of being guilty makes that you personal data should be published?). Another one is house value valuation.
You don’t discuss it, but your images contain the concepts of red/blue/green button and this is an interesting thing: open _personal_ data, data that concerns myself and that I should be able to retrieve as openly as I do for government data (but should not be available to everybody). Integrated with open personal data could be integrated a “share” option that allows me to share the data with some specific organizations (universities for research for example). Apps like Mint show that there would be a great deal of opportunities for these data.
Updated privacy and ATI legislation has been urgently required for some time, but it seems as if we’re getting closer to some kind of tipping point (which will most likely be ugly). Better to think about this now than in response to some kind of privacy disaster.
You might be interested in reading this article about differential privacy, a concept which allows quantification of the risk of residual disclosure from a given database.
http://www.scientificamerican.com/article.cfm?id=privacy-by-the-numbers-a-new-approach-to-safeguarding-data&WT.mc_id=SA_DD_20121231&WT.mc_id=SA_emailfriend
A few comments, generally around the illustrations.
– I get the feeling that these were originally created for something else and re-used here. I, too, noticed the coloured button identification which was never explained in the text.
– I get the feeling that you *really* like the idea of politicians’ voting records being public. It’s included twice in each diagram that provides examples.
– I think it is worth including somehow the concept of “anonymized” data. In the areas of health, education and environment, where all your examples are completely outside the “open data” circles, there may be aggregate data which it would be socially beneficial to make open and which could be provided (with appropriate safeguards) without significant risk to privacy. I’m sure you know this, but I think it’s worth including it in a discussion of open data and privacy.
Er… a few comments.
1. I created these diagrams for this post. They are not re-used.
2. I included the coloured button identifications to spur interest – for some people they have meaning (they are ideas championed by the white house) and i didn’t have the time (and it didn’t fit into the flow) to spell out what they were.
3. While I do like politicians voting records I don’t think they are particularly special. In fact, you’ll notice that everything in both diagrams are the same so I think it is interesting that you’ve zeroed in on that example.
4. I did abbrivate the personal data examples in order fit in the text in with the new purchasable data – so I resorted to the buttons cause it was easy.
5. Yes, the anonymized data could be open – I think this is an interesting point and something the diagram fails to capture as well as it could – but my main point was talking about privacy and personally identifiable data sets, so that’s why they ended up there.
Er.. each diagram with examples has three examples of open data:
– (top) public art locations
– (middle) politicians voting records
– (bottom) politicians voting records
Note the similarity in the middle and bottom examples. That’s what I was referring to.
Hey there @david_a_eaves:disqus ,
Great thought-provoking post. Read it twice over lunch and I’m still wondering where you fall on this specific story/database of the gun owners?
You point to intentions as part of the way that people will evaluate data initiatives like this, but my sense is that most similar news apps have a take on the data, though some organizations might try to be more objective than others. Certainly, when ProPublica published the “Dollars for Docs” database, they had a perspective on the question of pharmaceutical payments to physicians, no? That data was also public, but much harder to get at, and actually — in my opinion — said a lot more about the people in the database than this gun map does.
I’m also curious about this “business license data:” can you provide some examples of what you’re referring to here, as your point is a bit fuzzy without the specifics of what data you’re thinking about in that context.
Thanks again. Enjoyable read.
Phillip.
I’d also like to hear some opinion on the gun data :)
Business license data is usually municipal / provincial / federal level business licenses, incorporations, etc. all of which must be filed and have a variety of information, like type of business, directors, address, and so on.
I also think that should be open. It’s already public, it’s just not online and open in most cases.
Business addresses are some times also home addresses, which is where some of the issue comes from, I suspect.
Pingback: Things You’ll Find Interesting January 7, 2013 | Chuq Von Rospach, Photographer and Author
Pingback: Privately counted | Uncounted
In regards to the credit score comment, there seems to be little regulation on this. I was recently turned down for credit even though I have a great credit score. When I inquired as to the reason, I was told my address didn’t match what Equifax had on file. Upon further investigation, Equifax had switched my current and former addresses. Is there no obligation for Equifax etc. to maintain ACCURATE data? And how has it come that Equifax’s information has become the reality, and I should have to “prove” that my address is my address? Shouldn’t it be Equifax that proves they have correct data?
Edited to add: The result of this is that my credit score has been dinged with this useless hit. I wasn’t even given the opportunity to respond, just flat-out refused. Equifax SELLS my information, but I’m expected to ensure their database is accurate for them???