I love Mozilla. Any reader of this blog knows it. I believe in its mission, I find the organization totally fascinating and its processes engrossing. So much so I spend a lot of time thinking about it – and hopefully, finding ways to contribute.
I’m also a big believer in data. I believe in the power of evidence-based public policy (hence my passion about the long-form census) and in the ability of data to help organizations develop better products, and people make smarter decisions.
Happily, a few months ago I was able to merge these two passions: analyzing data in an effort to help Mozilla understand how to improve Firefox. It was fun. But more importantly, the process says a lot about the potential for innovation open to organizations that cultivate an engaged user community.
So what happened?
In November 2010, Mozilla launched a visualization competition that asked: How do People Use Firefox? As part of the competition, they shared anonymous data collected from Test Pilot users (people who agreed to share anonymous usage data with Mozilla). Working with my friend (and quant genius) Diederik Van Liere, we analyzed the impact of add-on memory consumption on browser performance to find out which add-ons use the most memory and thus are most likely slowing down the browser (and frustrating users!). (You can read about our submission here).
But doing the analysis wasn’t enough. We wanted Mozilla engineers to know we thought that users should be shown the results – so they could make more informed choices about which add-ons they download. Our hope was to put pressure on add-on developers to make sure they weren’t ruining Firefox for their users. To do that we visualized the data by making a mock up of their website – with our data inserted.
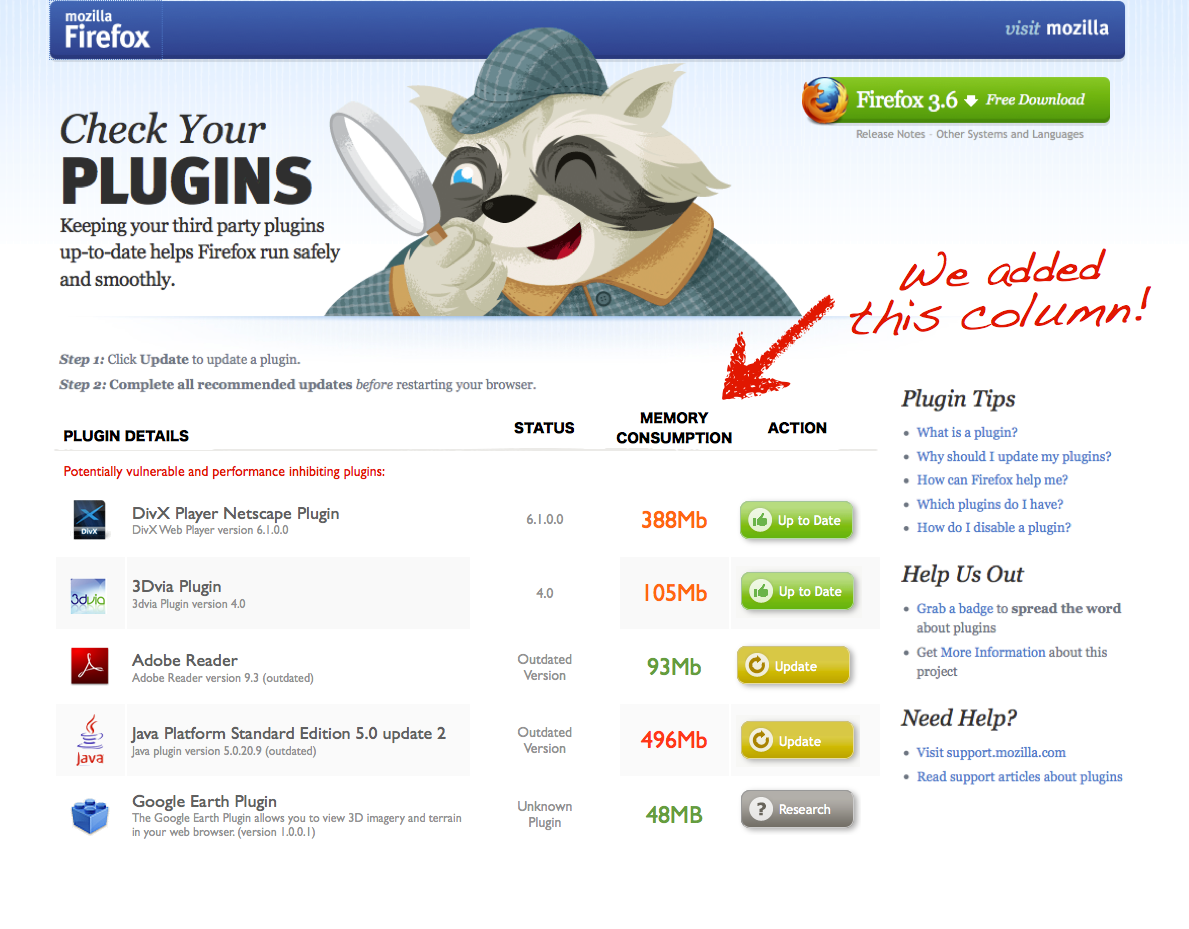
For our efforts, we won an honourable mention. But winning a prize is far, far less cool than actually changing behaviour or encouraging an actual change. So last week, during a trip to Mozilla’s offices in Mountain View, I was thrilled when one of the engineers pointed out that the add-on site now has a page where they list add-ons that most slow down Firefox’s start up time.
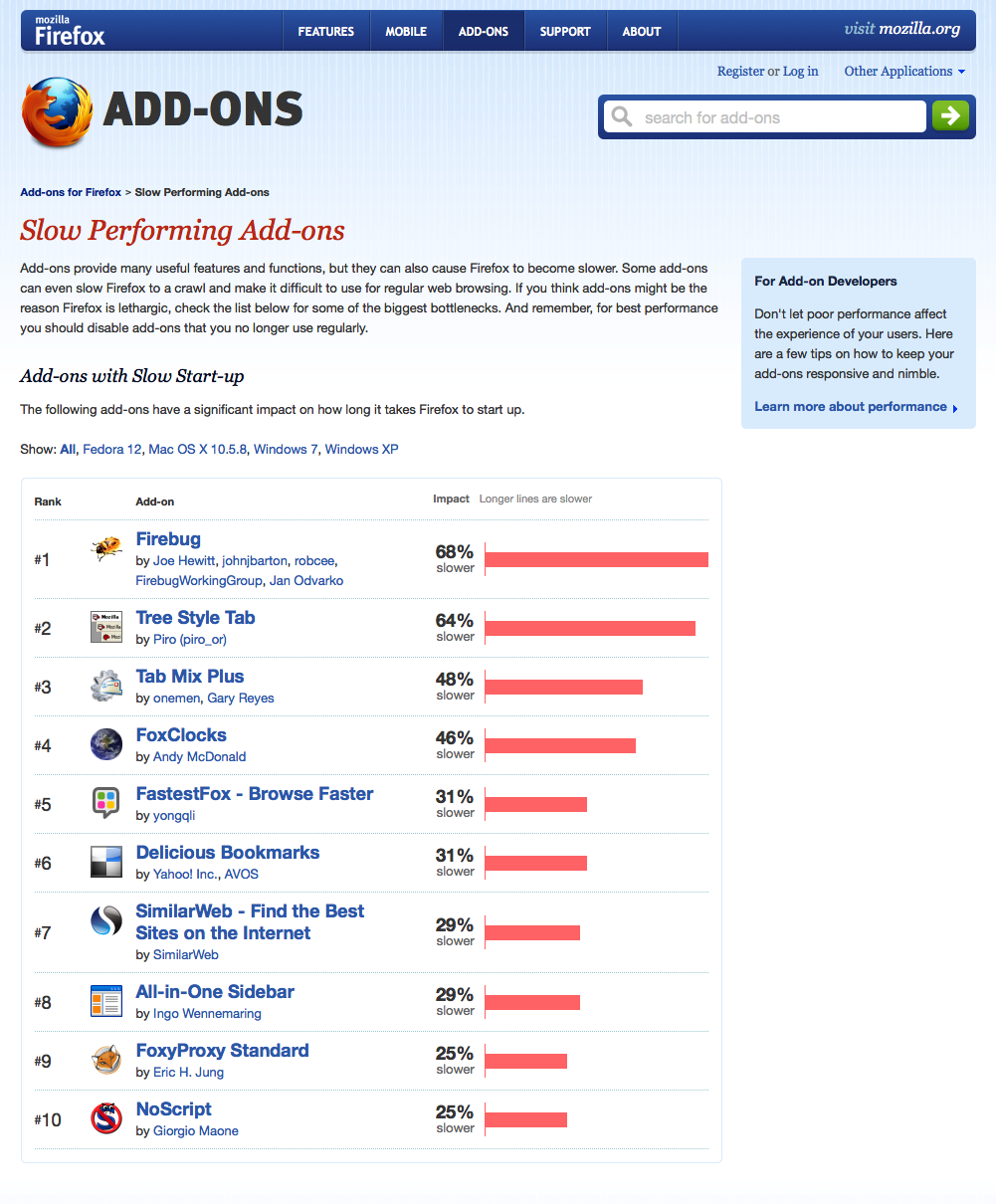
(Sidebar: Anyone else find it ironic that “FastestFox: Browse Faster” is #5?)
This is awesome! Better still, in April, Mozilla launched an add-on performance improvement initiative to help reduce the negative impact add-ons can have on Firefox. I have no idea if our submission to the visualization competition helped kick-start this project; I’m sure there were many smart people at Mozilla already thinking about this. Maybe it was already underway? But I like to believe our ideas helped push their thinking – or, at least, validated some of their ideas. And of course, I hope it continues to. I still believe that the above-cited data shouldn’t be hidden on a webpage well off the beaten path, but should be located right next to every add-on. That’s the best way to create the right feedback loops, and is in line with Mozilla’s manifesto – empowering users.
Some lessons (for Mozilla, companies, non-profits and governments)
First lesson. Innovation comes from everywhere. So why aren’t you tapping into it? Diederik and I are all too happy to dedicate some cycles to thinking about ways to make Firefox better. If you run an organization that has a community of interested people larger than your employee base (I’m looking at you, governments), why aren’t you finding targeted ways to engage them, not in endless brainstorming exercises, but in innovation challenges?
Second, get strategic about using data. A lot of people (including myself) talk about open data. Open data is good. But it can’t hurt to be strategic about it as well. I tried to argue for this in the government and healthcare space with this blog post. Data-driven decisions can be made in lots of places; what you need to ask yourself is: What data are you collecting about your product and processes? What, of that data, could you share, to empower your employees, users, suppliers, customers, whoever, to make better decisions? My sense is that the companies (and governments) of the future are going to be those that react both quickly and intelligently to emerging challenges and opportunities. One key to being competitive will be to have better data to inform decisions. (Again, this is the same reason why, over the next two decades, you can expect my country to start making worse and worse decisions about social policy and the economy – they simply won’t know what is going on).
Third, if you are going to share, get a data portal. In fact, Mozilla needs an open data portal (there is a blog post that is coming). Mozilla has always relied on volunteer contributors to help write Firefox and submit patches to bugs. The same is true for analyzing its products and processes. An open data portal would enable more people to help find ways to keep Firefox competitive. Of course, this is also true for governments and non-profits (to help find efficiencies and new services) and for companies.
Finally, reward good behaviour. If contributors submit something you end up using… let them know! Maybe the idea Diederik and I submitted never informed anything the add-on group was doing; maybe it did. But if it did… why not let us know? We are so pumped about the work they are doing, we’d love to hear more about it. Finding out by accident seems like a lost opportunity to engage interested stakeholders. Moreover, back at the time, Diederik was thinking about his next steps – now he works for the Wikimedia Foundation. But it made me realize how an innovation challenge could be a great way to spot talent.




