This article was written by David Eaves, lecturer at the Harvard Kennedy School, Tom Loosemore, Partner at Public Digital, with Tommaso Cariati and Blanka Soulava, students at the Harvard Kennedy School. It first appeared in Apolitical.
Government digital services have proven critical to the pandemic response. As a result, the operational pace of launching new services has been intense: standing up new services to provide emergency funds, helping people stay healthy by making critical information accessible online, reducing the strain on hospitals with web and mobile based self-assessment tools and laying the groundwork for a gradual reopening of society by developing contact tracing solutions.
To share best practices and discuss emerging challenges Public Digital and the Harvard Kennedy School co-hosted a gathering of over 60 individuals from digital teams from over 20 national and regional governments. On the agenda were two mini-case studies: an example of collaboration and code-sharing across Canadian governments and the privacy and interoperability challenges involved in launching contract tracing apps.
We were cautious about convening teams involved in critical work, as we’re aware of how much depends on them. However, due to the positive feedback and engaging learnings from this session we plan additional meetings for the coming weeks. These will lead up to the annual Harvard / Public Digital virtual convening of global digital services taking place this June. (If you are part of a national or regional government digital service team and interested in learning more please contact us here.)
Case 1: sharing code for rapid response
In early March as the Covid-19 crisis gained steam across Canada, the province of Alberta’s non-emergency healthcare information service became overwhelmed with phone calls.
Some calls came from individuals with Covid-19 like symptoms or people who had been exposed to someone who had tested positive. But many calls also came from individuals who wanted to know whether it was prudent to go outside, who were anxious, or had symptoms unrelated to Covid-19 but were unaware of which symptoms to look out for. As the call center became overwhelmed it impeded their ability to help those most at risk.
Enter the Innovation and Digital Solutions from Alberta Health Services, led by Kass Rafih and Ammneh Azeim. In two days, they interviewed medical professionals, built a prototype self-assessment tool and conducted user-testing. On the third day, exhausted but cautiously confident, they launched the province of Alberta’s Covid-19 Self Assessment tool. With a ministerial announcement and a lucky dose of Twitter virality, they had 300k hits in the first 24h, rising to more than 3 million today. This is in a province with a total population of 4.3 million residents.

But the transformative story begins five days later, when the Ontario Digital Service called and asked if the team from Alberta would share their code. In a move filled with Canadian reasonableness, Alberta was happy to oblige and uploaded their code to GitHub.
Armed with Alberta’s code, the Ontario team also moved quickly, launching a localised version of the self-assessment tool in three days on Ontario.ca. Anticipating high demand, a few days later they stood up and migrated it to a new domain — Covid-19.ontario.ca — which has since evolved into a comprehensive information source for citizens, hosting information such as advice on social distancing or explanations about how the virus works with easy to understand answers.
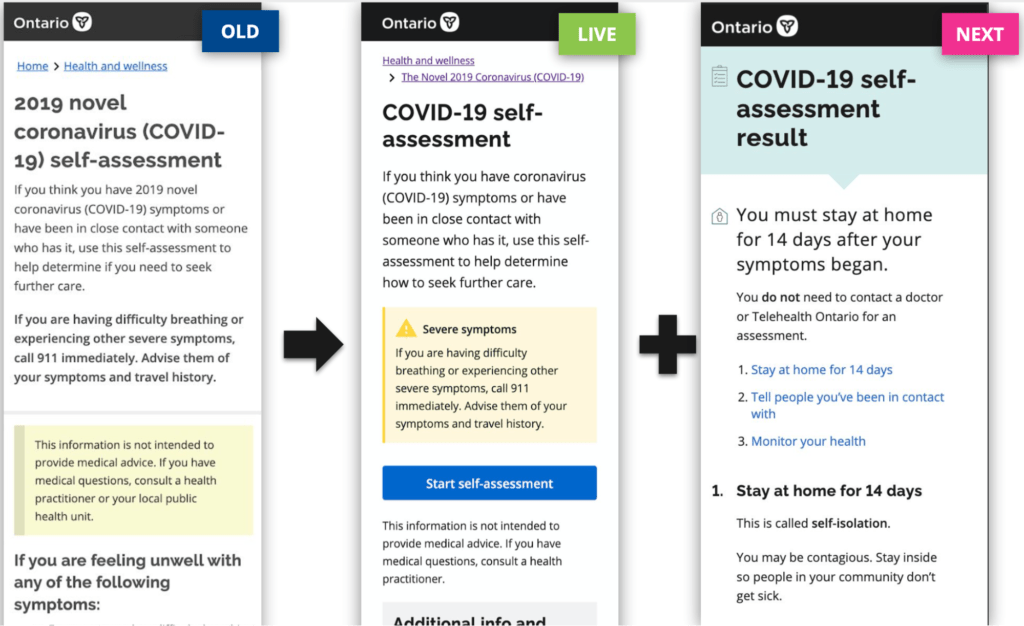
The evolution of the Ontario Covid-19 portal information page, revised for ease of understanding and use
The Ontario team, led in part by Spencer Daniels, quickly iterated on the site, leveraging usage data and user feedback to almost entirely rewrite the government’s Covid-19 advice in simpler and accessible language. This helped reduce unwarranted calls to the province’s help lines.
Our feeling is that governments should share code more often. This case is a wonderful example of the benefits it can create. We’ve mostly focused on how code sharing allowed Ontario to move more quickly. But posting the code publicly also resulted in helpful feedback from the developer community and wider adoption. In addition, several large private sector organisations have repurpose that code to create similar applications for their employees and numerous governments on our call expressed interest in localising it in their jurisdiction. Sharing can radically increase the impact of a public good.
The key lesson. Sharing code allows:
- Good practices and tools to be adopted more widely — in days, not weeks
- Leveraging existing code allows a government team to focus on user experience, deploying and scaling
- The crisis is a good opportunity to overcome policy inertia around sharing or adopting open source solutions
- Both digital services still have their code on GitHub (Ontario’s can be found here and Alberta’s here).
The amazing outcome of this case is also a result of the usual recommendations for digital services that both Alberta and Ontario executed so well: user-centered design, agile working and thinking, working in cross-functional teams, embedding security and privacy by design and using simple language.
Case 2: Contact tracing and data interoperability
Many countries hit hard by the coronavirus are arriving at the end of the beginning.
The original surge of patients is beginning to wane. And then begins a complicated next phase. A growing number of politicians will be turning to digital teams (or vendors) hoping that contact tracing apps will help re-open societies sooner. Government digital teams need to understand the key issues to ensure these apps are deployed in ways that are effective, or to push back against decision makers if these apps will compromise citizens’ trust and safety.
To explore the challenges contact tracing apps might create, the team from Safe Paths, an open source, privacy by design contact tracing app built by an MIT led team of epidemiologists, engineers, data scientists and researchers, shared some early lessons. On our call, the Safe Paths team outlined two core thoughts behind their work on the app: privacy and interoperability between applications.
The first challenge is the issue of data interoperability. For large countries like the United States, or regions like Europe where borders are porous, contact tracing will be difficult if data cannot be scaled or made interoperable. Presently, many governments are exploring developing their own contact tracing apps. If each has a unique approach to collecting and structuring data it will be difficult to do contact tracing effectively, particularly as societies re-open.
Apple and Google’s recent announcement on a common Bluetooth standard to enable interoperability may give governments and a false sense of security that this issue will resolve itself. This is not the case. While helpful, this standard will not solve the problem of data portability so that a user could choose to share their data with multiple organisations. Governments will need to come together and use their collective weight to drive vendors and their internal development teams towards a smaller set of standards quickly.
The second issue is privacy. Poor choices around privacy and data ownership — enabled by the crisis of a pandemic — will have unintended consequences both in the short and long term. In the short term, if the most vulnerable users, such as migrants, do not trust a contact app they will not use it or worse, attempt to fool it, degrading data collection and undermining the health goals. Over the long term, decisions made today could normalise privacy standards that run counter to the values and norms of free liberal societies, undermining freedoms and the public’s long term trust in government. This is already of growing concern to civil liberties groups.
One way Safepaths has tried to address the privacy issue is by storing users data on their device and giving the user control over how and when data is shared in a de-identified manner. There are significant design and policy challenges in contact apps. This discussion is hardly exhaustive, but they need to start happening now, as decisions about how to implement these tools are already starting to be made.
Finally, the Safepaths team noted that governments have a responsibility in ensuring access to contact tracing infrastructure. For example, they struck agreements to zero-rate — e.g. make the mobile data needed to download and run the app free of charge — in a partner Caribbean country to minimise any potential cost to the users. Without such agreements, some of the most vulnerable won’t have access to these tools.
Conclusions and takeaways
This virtual conversation was the first in a series that will be held between now and the annual June Harvard / Public Digital convening of global digital services. We’ll be hosting more in the coming weeks and months.
Takeaways:
- The importance of collaboration and sharing code within and between countries. This was exemplified by code sharing between the Canadian provinces and by the hope that this can become an international effort.
- Importance of maintaining user-centered focus despite of the time pressure and fast-changing environment that requires quick implementation and iteration. Another resource here is California’s recently published crisis digital standard.
- Privacy and security must be central to solutions that help countries deal with Covid-19. The technology exists to make private and secure self-assessment forms and contact tracing apps. The challenge is setting those standards early and driving global adoption of them.
- Interoperability of contact tracing solutions will be pivotal to tackle a pandemic that doesn’t borders, cultures, or nationality. As the SafePaths team highlighted, this is a global standard-setting challenge.
Harvard and Public Digital are planning to host another event on this series on the digital response to Covid-19, sign up here if you’d like to participate in future gatherings! — David Eaves and Tom Loosemore with Tommaso Cariati and Blanka Soulava
This piece was originally published on Apolitical.