Last weekend I helped host an Open Data Day in Vancouver. With the generous support of Domain7, who gave us a place to host talks and hack, over 30 Vancouverites braved the sleet and snow to spend the day sharing ideas and working on projects.
We had opening comments from Andy Yan – whose may be the most prolific user of Open Data in Vancouver, possibly Canada. I encourage you to check out his work here. We were also incredibly lucky to have Jeni Tennison – the Technical Director of the Open Data Institute – onsite to talk to participants about the ODI.
After the opening talks, people simply shared what they hoped to work on and people just found projects to contribute to. Minimal organization was involved… and here a taste of the awesome projects that got worked on! Lots of ideas here for other communities.
1. Open Data Licenses Resource: JSON + search + compatibility check = Awesome.
Kent Mewhort, who recently moved to Vancouver from Ottawa (via the Congo) updated his ongoing CLIPol project by adding some of the recently published licenses. If you’ve not seen CLIPol it is… awesome. It allows you to easily understand and compare the restrictions and rights of many open government licenses.

Better still CLIPol also lets you to see how compatible a license is (see example here). Possibly the best tool of all is one that allows you to determine what license you can apply to your re-mixed work in a way that is compliant with the original licenses (check out that tool here – screenshot below).
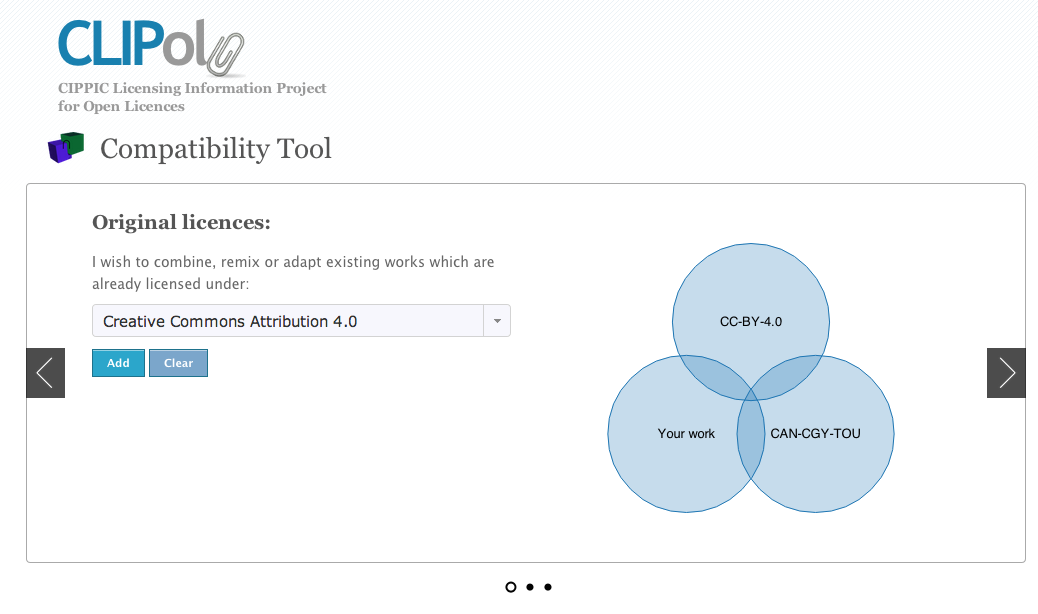
CLIPol is just such a fantastic tool – can’t recommend it enough and encourage people to add more licenses to it.
2. Vancouver in MineCraft
I have previously written about how Minecraft is being used to help in public consultations and urban planning – I love how the game becomes a simple tool that enables anyone to shape the environment.
So I was crazy excited I heard that Ryan Smith (aka Goldfish) had used the City of Vancouver’s open elevation data to recreate much of the city in Minecraft.
Below is a photo of Ryan presenting at the end of the day. The projection behind him shows Stanley park, near Siwash Rock. The flat feature at the bottom is the sea wall. Indeed Ryan notes that the sea wall makes for one of the clearest features since it creates almost perfectly flat structure along the city’s coast.

3. Vancouver’s Capital Budget Visualized in Where Does my Money Go
It is hard to imagine a project going better. I’m going to do a separate blog post on it.
This is a project I’ve always wanted to do – create a bubble tree visualization with Where Does my Money Go. Fortunately two developers – Alexandre Dufournet and Luc Lussier – who had never hacked on open data jumped on the idea. With help from City of Vancouver’s staff who were on site, I found a PDF of the capital budget which we then scraped.

The site is not actually live, but for developers who are interested in seeing this work (hint, hint City of Vancouver staff) you can grab their code from github here.
4. Monitoring Vancouver’s Bike Accident Data – Year 3
Eric Promislow has been coming to Open Data Hack-a-thons ever since Luke Closs and I started organizing them in 2009. During the first Open Data Day in 2011 you can read in my wrap up post about a bike accident monitoring website Eric created that day which Eric would eventual name Bent Frame. Well, Bent Frame has been live ever since and getting bigger. (Eric blogs about it here)
Each open data day, Eric updates Bent Frame with new data from ICBC – the province’s insurance monopoly. With over 6 years of data now in Eric is starting to be able to analyze trends – particularly around the decline of bike accidents along many roads with bike lanes, and an increase in accidents where the bike lanes end.

I initially had conversations with ICBC to persuade them to share their data with Eric and they’ve been in touch with him ever since, passing along the data on a regular basis. It is a real example of how an active citizen can change an organization’s policies around sharing important data that can help inform public policy debates.
5. ProactiveDisclosure.ca – Making government information easier to search
Kevin McArthur is the kind of security guy most governments dreads having around but should actually love (example his recent post on e-voting). He continued to hack on one of his side projects: proactivedisclosure.ca. The site is a sort of front end for open data sets, making it easier to do searches based on people or companies. Thus, want to find all the open data about a specific minister… proactive disclosure organizes it for you.

Kevin and a small team of players uploaded more data into their site and allowed it to consume unstructured data. Very cool stuff.
6. Better Open Data Search
Herb Lainchbury – another fantastic open data advocate – worked on a project in which he tried to rethink what an open data search engine would look like. This is a topic that I think matters A LOT. There is simply not a lot of good ways to find data that you are interested in.
Herb’s awesome insight was invert the traditional way of thinking about data search. He created a search engine that didn’t search for the data set keywords or titles, but rather searched the meta data exclusively.
One interesting side outcome of this approach is that it made related data sets easier and, made locating identical data sets but from different years a snap. As Herb notes the meta data becomes a sort of “finger print” that makes it easy to see when it has been duplicated. (Quick aside rant: I loath it when governments releases 20 data files of the same data set – say crime data – with each file representing a different year and then claiming that it is 20 unique data sets in their catalogue. No. It is one data set. You just have 20 years of it. Sigh).
7. School Performance Chart
Two local video game programers – Louie Dinh and Raymond Huang – with no experience in open data looked around the BC Government Open Data catalogue and noticed the data on test scores. Since they attended school here in British Columbia they thought it might be interesting to chart the test scores to see how their own schools had preformed over time.
They were able to set up a site which graphed how a number of elementary schools had performed over time by looking at the standardized test scores.
This is just a great example of data as a gateway to learning. Here a simple hackathon project become a bridge for two citizens to dive into a area of public policy and learn more about it. No one is claiming that there chart is definitive, rather it is the start of a learning process around what matters and what doesn’t and what can be measured and what can’t in education.
Congratulations to everyone who participated in the day – thank you for making it such an amazing success!