I’ve just finished “Linked” by Albert-Laszlo Barabasi (review to come shortly) and the number of applications of his thesis are startling.
A New Map for Open Source Communities
The first that jumps to mind is how it nicely the book’s main point provides a map that explains both the growth and structure of open source communities. Most people likely assume that networks (such as an open source community) are randomly organized – with lots people in the network connected to lots of other people. Most likely, these connections would be haphazard, randomly created (perhaps when two people meet or work together) and fairly evenly distributed.

If an open-source community was organized randomly and experienced random growth, participants would join the community and over time connect with others and generate new relationships. Some participants would opt to create more relationships (perhaps because they volunteer more time), others would create fewer relationships (perhaps because they volunteer less time and/or stick to working with the same group of people). Over time, the law of averages should balance out active and non-active users.
New entrants would be less active in part because they possess fewer relationships in the community (let’s say 1 or 2 connections). However, these new entrants would eventually became more active as they made new relationships and became more connected. As a result they would join the large pool of average community members who would possess an average number of connections (say 10 other people) and who might be relatively active. Finally, at the other extreme we would find veterans and/or super active members. A small band of relatively well connected members who know a great deal of people (say 60 or even 80 people).
Map out the above described community and you get a bell curve (taken from the book Linked). A few users (nodes) with weak links and a few better connected than the average. The bulk of the community lies in the middle with most people possessing more or less the same number of links and contributing more or less the same amount as everyone else. Makes sense, right?
Or maybe not. People involved in open-source communities probably will remark that their community participation levels does not look like this. This, according to Barabasi, should not surprise us. Many networks aren’t structured this way. The rules that govern the growth and structure of many network – rules that create what Barabasi terms “scale-free networks” – create something that looks, and acts, very differently.
In the above graph we can talk about about the average user (or node) with confidence. And this makes sense… most of us assume that there is such thing as an average user (in the case of opensource movements, it’s probably a “he,” with a comp-sci background, and an avid Simpson’s fan). But in reality, most networks don’t have an average node (or user). Instead they are shaped by what is called a “power law distribution.” This means that there is no “average” peak, but a gradually diminishing curve with many, many, many small nodes coexisting with a few extremely large nodes.
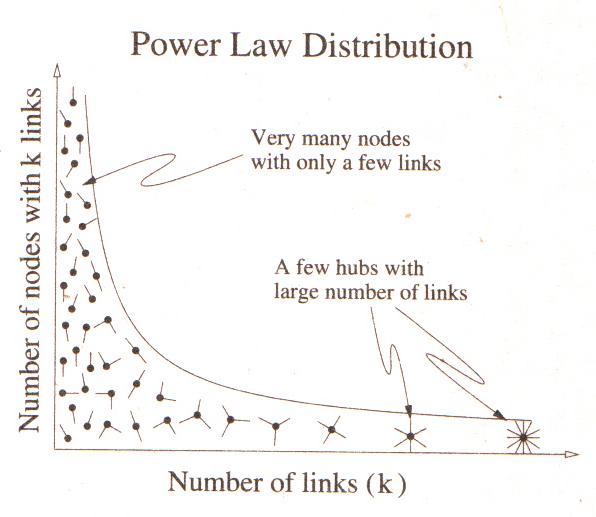
In an open source community this would mean that there are a few (indeed very few, in relation to the community’s size) power users and a large number of less active or more passive users.
Applying this description to the Firefox community we should find the bulk of users at the extreme left. People who – for example – are like me. They use Firefox and have maybe even registered a bug or two on Firefox’s Bugzilla webpage. I don’t know many people in the community and I’m not all the active. To my right are more active members, people who probably do more – maybe beta test or even code – and who are better connected in the community. At the very extreme and the super-users (or super nodes). These are people who contribute daily or are like Mike Shaver (bio, blog) and Mike Beltzner (bio, blog): paid employees of the Mozilla corporation with deep connections into the community.
Indeed, Beltzner’s presentation on the FireFox community (blog post here, presentation here and relevant slides posted below) lists a hierarchy of participation level that appears to mirror a power law distribution.

I think we can presume that those at the beginning of the slide set (e.g Beltzner, the 40 member Mozilla Dev Team and the 100 Daily Contributors) are significantly more active and connected within the community than the Nightly Testers, Beta Testers and Daily Users. So the FireFox community (or network) may be more accurately described by a Power Law Distribution.
Implications for Community Management
So what does this mean for open source communities? If Barabasi’s theory of networks can be applied to open source communities – there are at least 3 issues/ideas worth noting:
1. Scaling could be a problem
If open source communities do indeed look like “scale-free networks” then it maybe be harder then previously assumed to cultivate (and capitalize on) a large community. Denser “nodes” (e.g. highly networked and engaged participants) may not emerge. Indeed the existence of a few “hyper-nodes” (super-users) may actually prevent new super-users (i.e. new leaders, heavy participants) from arising since new relationships will tend to gravitate towards existing hubs.
Paradoxically, the problem may be made worse by the fact that most humans can only maintain a limited number of relationships at any given time. According to Barabasi, new users (or nodes) entering the community (or network) will generally attempt to forge relationships with hub-like individuals (this is, of course, where the information and decision-making resides). However, if these hubs are already saturated with relationships, then these new users will have hard time forging the critical relationships that will solidify their connection with the community.
Indeed, I’ve heard of this problem manifesting itself in open source communities. Those central to the project (the hyper nodes) constantly rely on the same trusted people over and over again. As a result the relationships between these individuals get denser while the opportunities for forging new relationships (by proving yourself capable at a task) with critical hubs diminishes.
2. Segmentation model
Under a Bell Shaped curve model of networks it made little sense to devote resource and energy to supporting and helping those who participate least because they made up a small proportion on the community. Time and energy would be devoted to enabling the average participant since they represented the bulk of the community’s participants.
A Power Law distribution radically alters the makeup of the community. Relatively speaking, there are an incredibly vast number of users/participants who are only passively and/or loosely connected to the community compared to the tiny cohort of active members. Indeed, as Beltzner’s slides point out 100,000 Beta testers and 20-30M users vs. 100 Daily Contributors and 1000 Regular Contributors.
The million dollar question is how do we move people up the food chain? How do we convert users and Beta testers and contributors and daily contributors? Or, as Barabasi might put it: how do increase nodes density generally and the number of super-nodes specifically?Obviously Mozilla and others already do this, but segmenting the community – perhaps into the groups laid out by Beltzner – and providing them with tools to not only perform well at that level, but that enable them to migrate up the network hierarchy is essential. One way to accomplish this task would be to have more people contributing to a given task, however, another possibility (one I argue in an earlier blog post) is to simply open source more aspects of the project, including items such as marketing, strategy, etc…
3. Grease the networks nodes
Finally, another way to over come the potential scaling problem of open source is to improve the capacity of hubs to handle relationships thereby enabling them to a) handle more and/or b) foster new relationships more effectively. This is part of what I was highlighting on my post about relationship management as the core competency of open source projects.
Conclusion
This post attempts to provide a more nuanced topology of open source communities by describing them as scale-free networks. The goal is not to ascertain that there is some limit to the potential of open source communities but instead to flag and describe possible structural limitations so as to being a discussion on how they can be addressed and overcome. My hope is that others will find this post interesting and use its premise to brainstorm ideas for how we can improve these incredible communities.
As a final note, given the late hour, I’m confident there may be a typo or two in the text, possible even a flawed argument. Please don’t hesitate to point either out. I’d be deeply appreciative. If this was an interesting read you may find – in addition to the aforementioned post on community management – this post on collaboration vs cooperation in open source communities to be interesting.
