One of the keys to making an open source project work is getting feedback from users and developers about problems (bugs) in the code or system. Mozilla (the organization behind Firefox and Thunderbird) uses Bugzilla, but organizations have developed a variety of systems for dealing with this issue. For example, many cities use 311. I’m going to talk about Bugzilla and Mozilla in this case, but I think the lessons can be applied more broadly for some of my policy geek friends.
So first, some first principles. Why does getting the system right matter? A few reasons come to mind:
- Engagement: For many people Bugzilla is their first contact with “the community.” We should want users to have a good experience so they feel some affinity towards us and we should want developers to have a great experience so that they want to deepen their level of participation and engagement.
- Efficiency: If you have the wrong or incomplete information it is hard (or impossible) to solve a problem, wasting the precious time of volunteer contributors.
I also concede that these two objectives may not always be congruent. Indeed, at times there may be trade offs between them… but I think there is a lot that can be done to improve both.
I’ve probably got more ideas than can fit (or should fit) into one post so I’m going to unload a few. I’ve got more that relate to the negotiation and empathetic approaches I talked about at the Mozilla Summit.
One additional thought. Please feel free to dump all over these. Some changes many not be as simple as I’ve assumed. Others may break or contravene important features I’m not aware of. Happy to engage people on these, please do not see them as an end point, but rather a beginning. My main goal with this first batch of suggestions was to find things that felt easier to do and so could be implemented quickly if there was interest and would help reduce transactions costs right away.
1. Simplifying Menus
First. I thought there were some simple changes that could render the interface cleaner and friendlier. It’s pretty text heavy – which is great for advanced users, but less inviting for newer users. More importantly however, we could streamline things to make it easier for people to onboard.
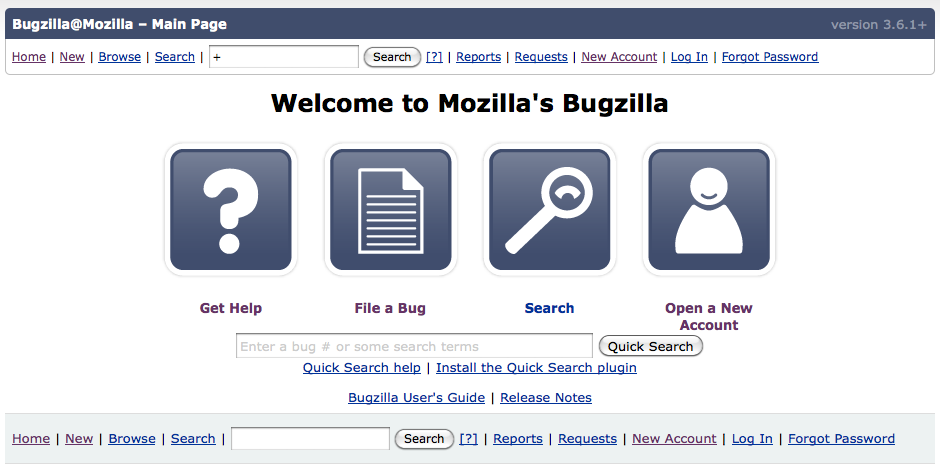
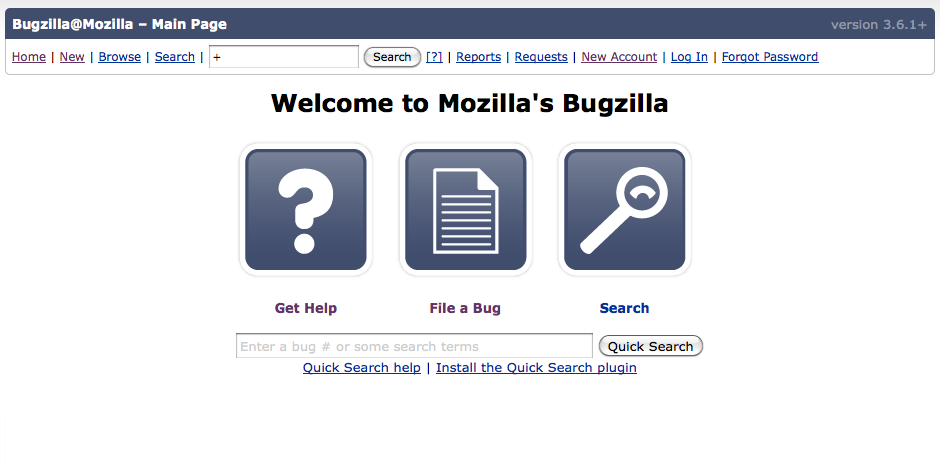
Take for example, the landing page of Bugzilla. It is unclear to me why “Open a new Account” should be on this page. Advanced users will know they want to file a bug, novices (who may be on the wrong site and who should be looking for support) might believe they have to open and account to get support. So why not eliminate the option altogether. You are going to get it anyways if you click on “File a bug.”
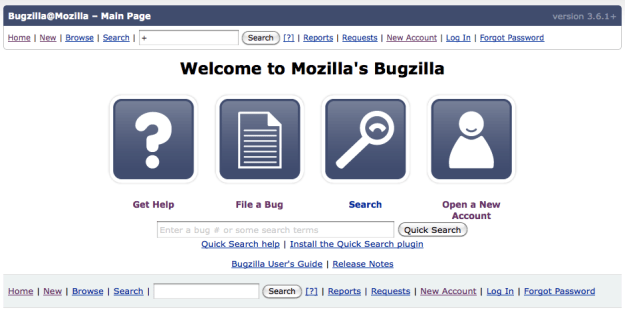
Current
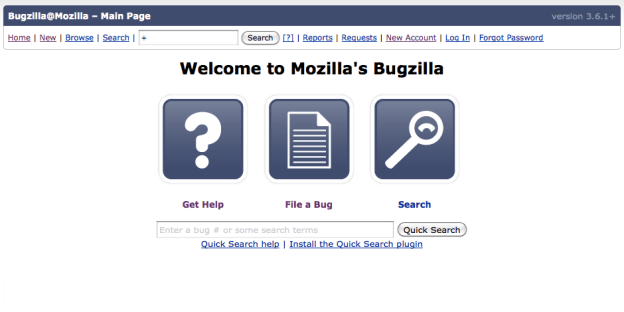
- Proposed
In addition, I got rid of the bottom menu bar (which I don’t think is necessary on this screenƒclu given all the features were along the top as well). I also ditched the Release Notes and User Guide for Bugzilla as I had doubts about whether users were, at this point and on this screen, looking for those things)
2. Gather more information about our users (and, while I’m at it, some more simplifying)
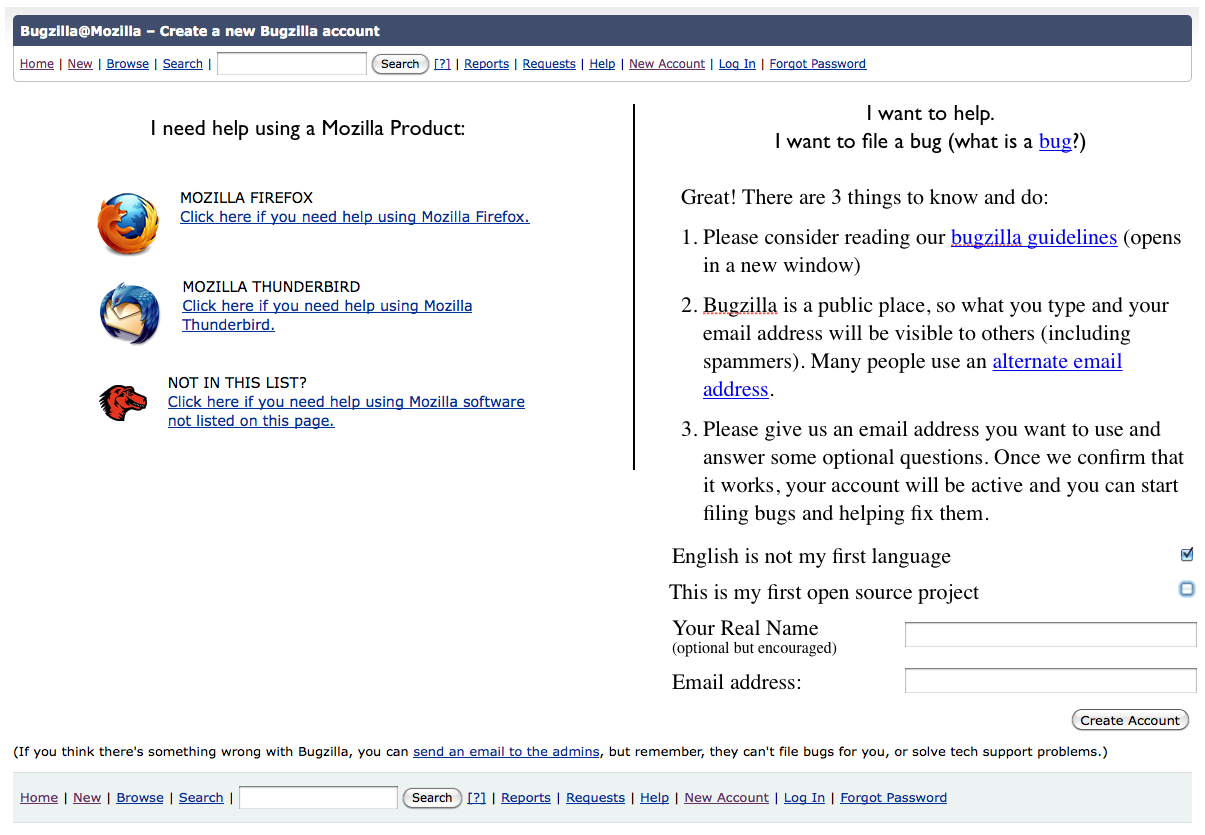
Once you choose to file a bug you get prompted to either log in or create an account. At this point, if you want to create an account. I thought this page was hard to read with the text spanning the whole width, plus, there is some good info we could gather about users at this point (the point it feels they are mostly likely going to add to their profile).

Current
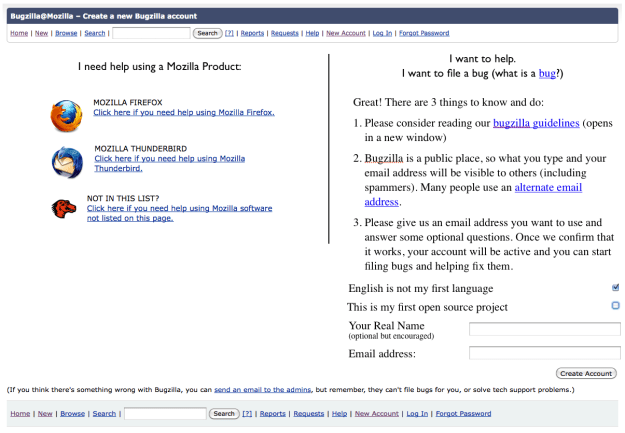
Proposed
Couple things a like about this proposed screen.
One, if you are a lost user just looking for support we likely snag you before you fill out a bugzilla account. My feeling is the bugzilla is a scary place that most users shouldn’t end up in… we need to give people lots of opportunities to opt for support before diving in, in case that is what they really need.
Second, in this proposed version we tell people to read the bugzilla guidelines and suggest using an alternate email before they punch their email into the email field box.
In addition, we ask the user for their real name now (as opposed to relying on them to fill it out later). This nudge feels important as the more people with real names on the site, the more I think people will develop relationships with one another. Finally we ask people if English is their second language and if this is their first open source project.
Finally, with the extra data fields we can help flag users as ESL or new and thus in need of more care, patience and help as they on-ramp (see screen shots below). We could even modify the Bugzilla guidelines to inform people to provide newbies and ESL’s with appropriate respect and support.
Current
Proposed

Proposed
I imagine that your “newbie” status would disappear either when you want (some sort of preference in your profile) or after you’ve engaged in a certain amount of activity.
3. Make life easier for users and the triage guys
Here is an idea I had talking with some of the triage guys at the Mozilla Summit.
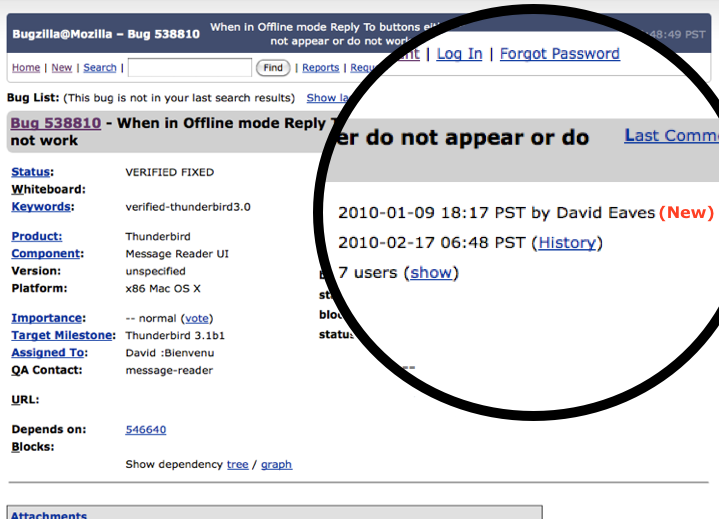
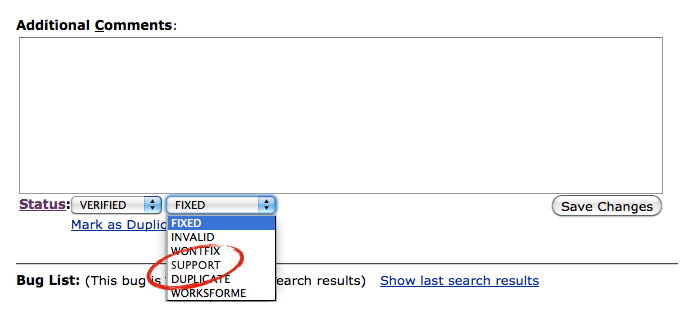
Let’s suppose that someone submits a bug that isn’t really a bug but a support issue. I’m informed that this happens with a high degree of frequency. Would it be nice if, with a click of a mouse, the triage guys could move that bug out of Bugzilla and into a separate database (ideally this would be straight into SUMO, but I respect that this might not be easy – so just moving it to a separate database and de-cluttering bugzilla would be a great first start – the SUMO guys could then create a way to import it). My sense is that this simply requires creating a new resolution field – I’ve opted to call it “Support” but am happy to name it something else.

Current
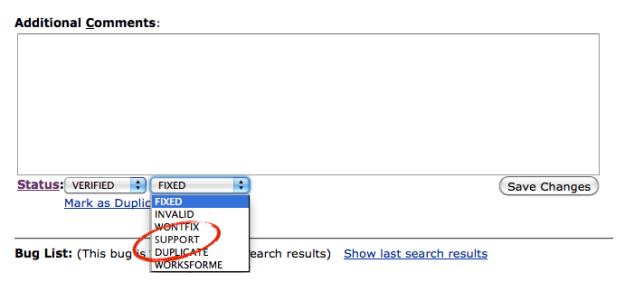
Proposed
This feels like a simple fix and it would quickly move a lot of bugs that are cluttering up bugzilla… out. This is important as searches for bugs often return many results that are support oriented, making it harder to find the bugs you are actually searching for. Better still, it would get them somewhere where they could more likely help users (who are probably waiting for us to respond).
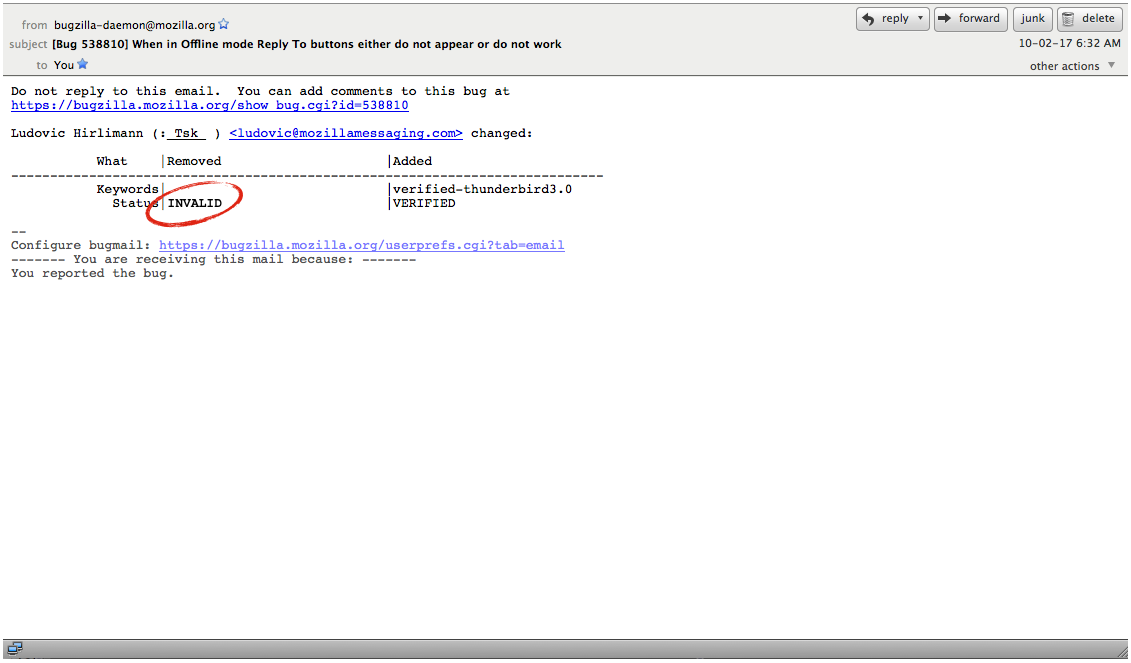
Of course, presently bugzilla will auto generate an email that looks like the first one and this isn’t going to help. So what if we did something else?
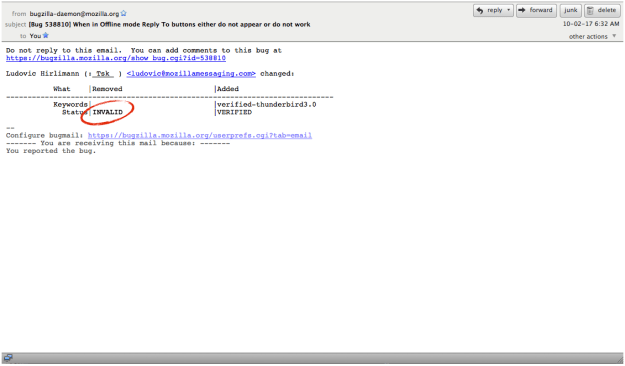
Current
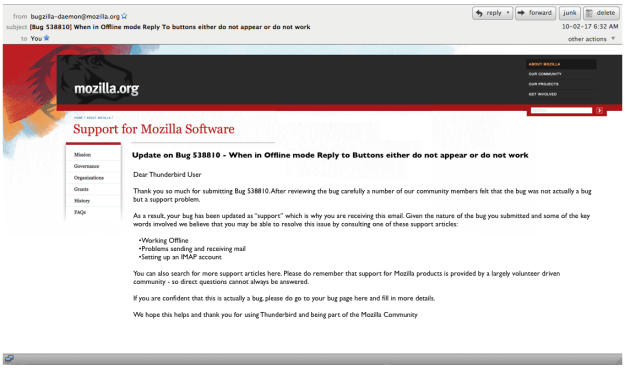
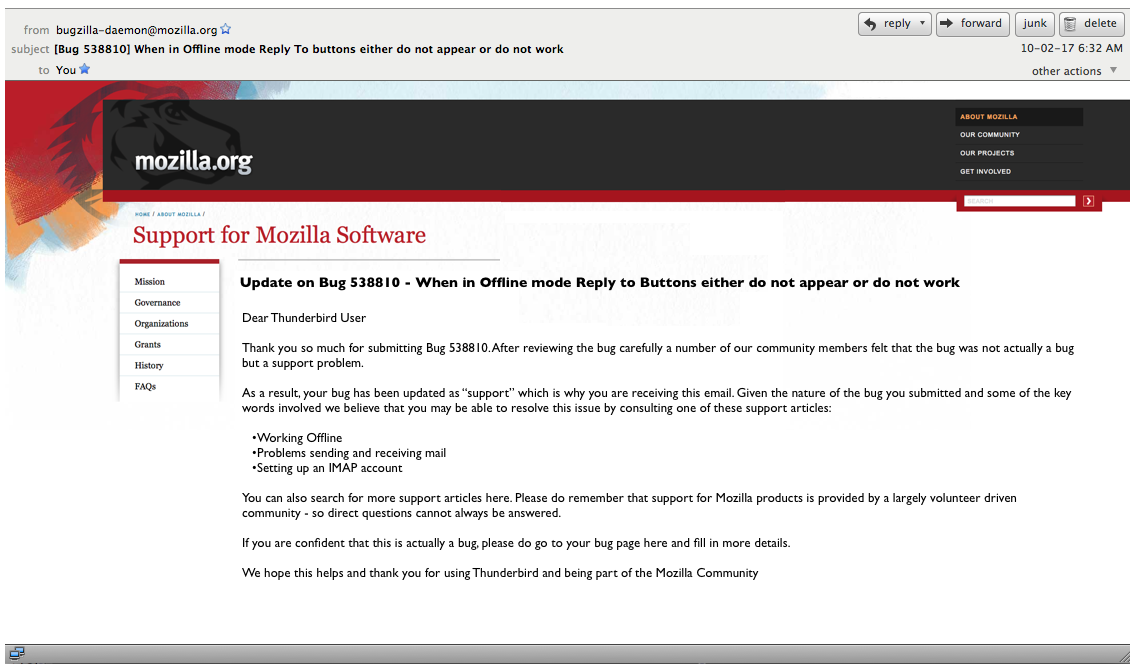
Proposed
Here is the auto-generated email I think we should be sending users whos bugs get sent to SUMO. I’ve proposed a few things.
First, if these are users who’ve submitted inappropriate bugs and who really need support, giving them a bugzilla email isn’t going to help them, they aren’t even going to know how to read it.
Second, there is an opportunity to explain to them where they should go for help – I haven’t done that explicitly enough in this email – but you get the idea
Third, when the bug gets moved to SUMO it might be possible to do a simple key word analysis of the bug and, from that, determine what are the most likely support articles they are looking for. Why don’t we send them the top 3 or 5 as hyperlinks in the email?
Fourth, if this really is a bug from a more sophisticated user, we give them a hyperlink back to bugzilla so they can make a note or comment.
What I like about this is it is customized engagement at a low cost. More importantly, it helps unclutter things while also making us more responsive and creating a better experience for users.
4. Make Bugzilla Celebrate, enhance our brand and build community
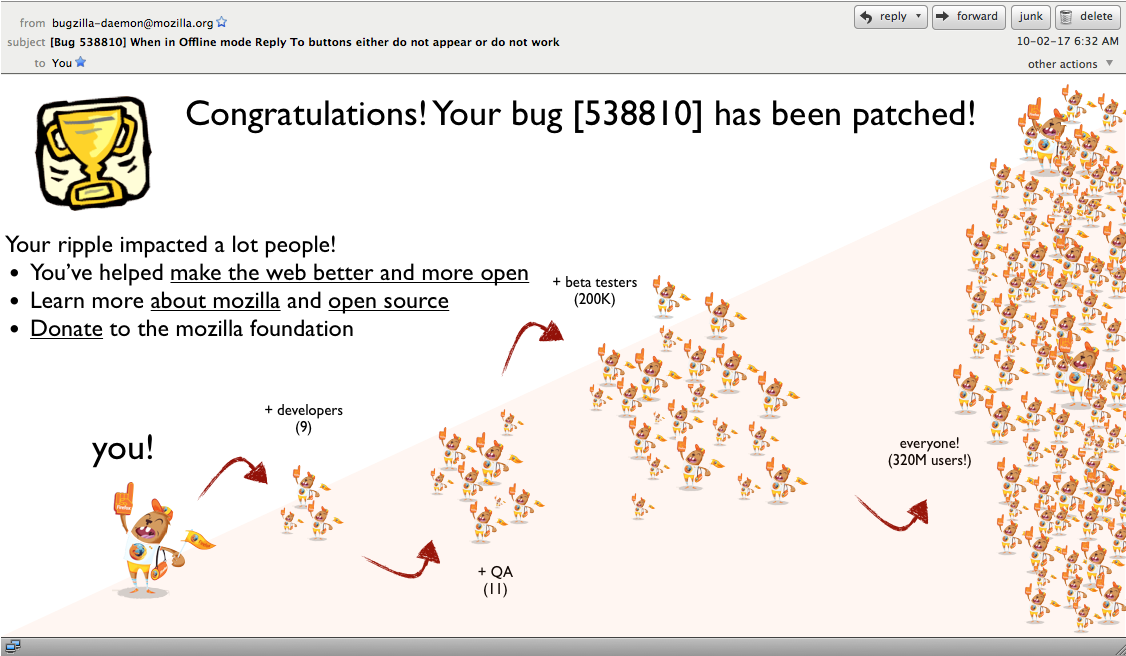
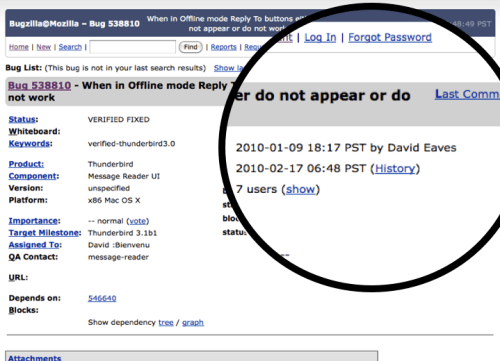
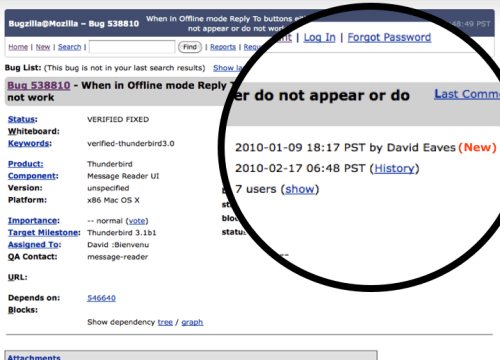
Okay, so here’s the thing that really bugs me about bugzilla. If we want to be onramping people and building community, shouldn’t we celebrate people’s successes? At the moment this is the email you get from Bugzilla when a bug you’ve submitted gets patched:

BORING! Here, at the moment of maximum joy, especially for casual or new bugzilla participants we do nothing to engage or celebrate.
This, is what I think the auto-generated bugzilla email should look like.

Yes, I agree that hard core community members probably won’t care about these types of bugs, but for more casual participants this is an opportunity to explain how open source and mozilla works (the graphic) as well as a chance to educate them. I’ve even been more explicit about this by offering links to a) explain the open web, b) learn about mozilla and open source; and c) donate to the foundation (given this is a moment of pride for many non-developer end users)
Again, I’m not overly attached to this design per se, it would just be nice to have something fun, celebratory and mozillaesque.
Okay, it is super late and I’m on an early flight tomorrow. Would love feedback on all or any of this for those who’ve made it this far. I’ll be sharing more thoughts, especially on empathetic nudges and community management in bugzilla ASAP.