(there is a section on this topic focused on governments below)
A hint of how social data could change journalism
Anyone who’s heard me speak in the last 6 months knows I’m excited about BuzzData. This week, while still in limited access beta, the site is showing hints its potential – and it still has only a few hundred users.
First, what is BuzzData? It’s a website that allows data to be easily uploaded and shared among any number of users. (For hackers – it’s essentially github for data, but more social). It makes it easy for people to copy data sets, tinker with them, share the results back with the original master, mash them up with other data sets, all while engaging with those who care about that data set.
So, what happened? Why is any of this interesting? And what does it have to do with journalism?
Exactly a month ago Svetlana Kovalyova of Reuters had her article – Food prices to remain high, UN warns – re-published in the Globe and Mail. The piece essentially outlined that food commodities were getting cheaper because of local conditions in a number of regions.
Someone at the Globe and Mail decided to go a step further and upload the data – the annual food price indices from 1990-present – onto the BuzzData site, presumably so they could play around with it. This is nothing complicated, it’s a pretty basic chart. Nonetheless a dozen or so users started “following” the dataset and about 11 days ago, one of them, David Joerg, asked:
The article focused on short-term price movements, but what really blew me away is: 1) how the price of all these agricultural commodities has doubled since 2003 and 2) how sugar has more than TRIPLED since 2003. I have to ask, can anyone explain WHY these prices have gone up so much faster than other prices? Is it all about the price of oil?
He then did a simple visualization of the data.
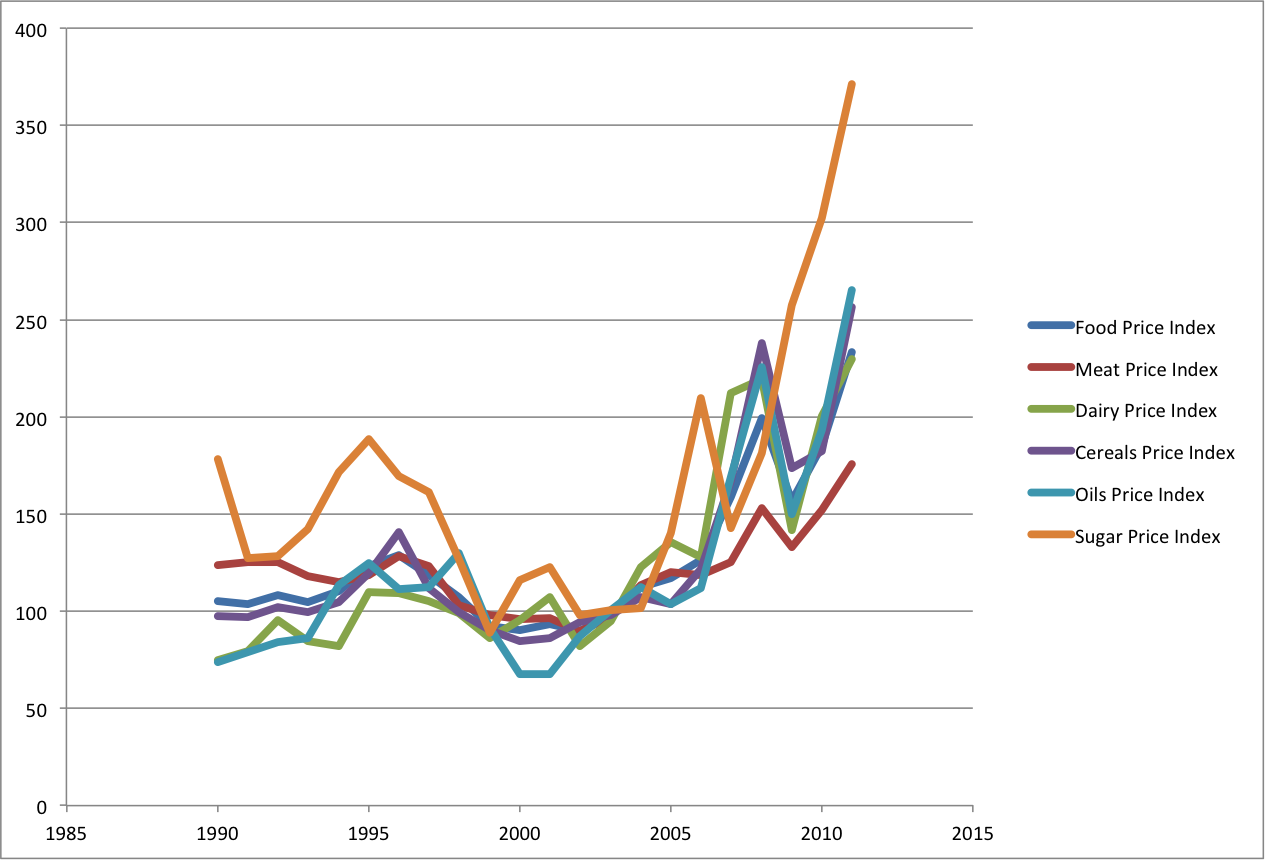
In response someone from the Globe and Mail entitled Mason answered:
Hi David… did you create your viz based on the data I posted? I can’t answer your question but clearly your visualization brought it to the forefront. Thanks!
But of course, in a process that mirrors what often happens in the open source community, another “follower” of the data shows up and refines the work of the original commentator. In this case, an Alexander Smith notes:
I added some oil price data to this visualization. As you can see the lines for everything except sugar seem to move more or less with the oil. It would be interesting to do a little regression on this and see how close the actual correlation is.
The first thing to note is that Smith has added data, “mashing in” Oil Price per barrel. So now the data set has been made richer. In addition his graph quite nice as it makes the correlation more visible than the graph by Joerg which only referenced the Oil Price Index. It also becomes apparent, looking at this chart, how much of an outlier sugar really is.
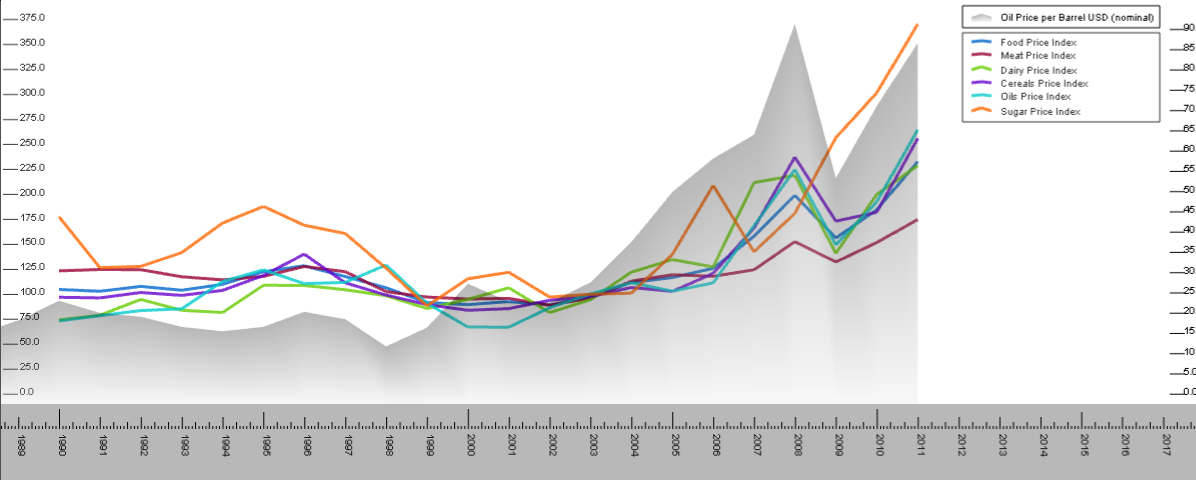
Perhaps some regression is required, but Smith’s graph is pretty compelling. What’s more interesting is not once is the price of oil mentioned in the article as a driver of food commodity prices. So maybe it’s not relevant. But maybe it deserves more investigation – and a significantly better piece, one that would provide better information to the public – could be written in the future. In either case, this discussion, conducted by non-experts simply looking at the data, helped surface some interesting leads.
And therein lies the power of social data.
With even only a handful of users a deeper, better analysis of the story has taken place. Why? Because people are able to access the data and look at it directly. If you’re a follower of Julian Assange of wikileaks, you might call this scientific journalism, maybe it is, maybe it isn’t, but it certainly is a much more transparent way for doing analysis and a potential audience builder – imagine if 100s or 1000s of readers were engaged in the data underlying a story. What would that do to the story? What would that do to journalism? With BuzzData it also becomes less difficult to imagine a data journalists who spends a significant amount of their time in BuzzData working with a community of engaged pro-ams trying to find hidden meaning in data they amass.
Obviously, this back and forth isn’t game changing. No smoking gun has been found. But I think it hints at a larger potential, one that it would be very interesting to see unlocked.
More than Journalism – I’m looking at you government
Of course, it isn’t just media companies that should be paying attention. For years I argued that governments – and especially politicians – interested in open data have an unhealthy appetite for applications. They like the idea of sexy apps on smart phones enabling citizens to do cool things. To be clear, I think apps are cool too. I hope in cities and jurisdictions with open data we see more of them.
But open data isn’t just about apps. It’s about the analysis.
Imagine a city’s budget up on Buzzdata. Imagine, the flow rates of the water or sewage system. Or the inventory of trees. Think of how a community of interested and engaged “followers” could supplement that data, analyze it, visualize it. Maybe they would be able to explain it to others better, to find savings or potential problems, develop new forms of risk assessment.
It would certainly make for an interesting discussion. If 100 or even just 5 new analyses were to emerge, maybe none of them would be helpful, or would provide any insights. But I have my doubts. I suspect it would enrich the public debate.
It could be that the analysis would become as sexy as the apps. And that’s an outcome that would warm this policy wonk’s soul.
