Better late than never, I’m going to do a few posts this week recapping a number of ideas and thoughts from Open Data Day 2013. As is most appropriate, I’m going to start the week with a recap of Vancouver – the Open Data Day event I attended and helped organize along with my friend Luke Closs and the very helpful and supportive staff at the City of Vancouver – in particular Linda Low and Kevin Bowers. I’ve got further thoughts about the day in general, its impact and some other ideas I’ll share in subsequent posts.
Vancouver! 2013!
What made Open Data Day in Vancouver great for me was that we had a range of things happen that really balanced time between “creating” (e.g. hacking) and engagement. As a result I’m diving this blog post into three parts: setting the scene, engagement and outcomes as well as sharing some lessons and best practices. My hope is that the post will make for fun reading for regular readers, but the lessons will prove helpful to future open data day organizers and/or plain old hackathon organizers.
Setting the scene

Despite competing with a somewhat rare sunny day in Vancouver at this time of year we had over 80 participants show up at City Hall, who graciously agreed to host the room. Backgrounds varied – we had environmentalists, college and university students, GIS types, open street mappers, journalists, statisticians among others. In addition, the city’s administration made a big commitment to be on hand. Over 20 staff were present, including one of the Deputy City Managers and a councillor – Andrea Reimer – who has been most active and supportive on the Open Data file. In addition we had a surprise guest – Federal Minister Tony Clement, who is the minister responsible for Open Data with the national government.
Our event was fairly loosely organized. We had a general agenda but didn’t over script anything. While Luke and I are comfortable with relatively flexible agenda for the day, we knew the unstructured nature of the event was a departure for some from the city and were grateful that they trusted us both with the format and with the fast, loose and informal way we sought to run the day.
Here are some high level lessons:
- When Possible host it Somewhere Meaningful. City Hall is always nice. Many attendees will have never engaged with local government before, this creates a space for them to learn and care about municipal government. It also reaffirms the broader culture changing and social/change oriented goals of an open data hackathon. Besides, who isn’t welcome at City Hall? It sets a great tone about who can come – which is pretty much anyone.
- Give the Politicians Some Room. Don’t be afraid to celebrate politicians and leaders who have championed the cause. Hackathons are about experimenting, not talking, so Andrea’s five minute talk at the beginning was the right mix of sincere engagement, enthusiasm and length.
- Don’t Only Attract Software Developers. Vancouver’s event was in part a success because of the diversity of participants. As you’ll see below, there are stories that emerged because we tried hard to engage non-software developers as well.
- Transit. This may sound obvious but… if you want to attract lots of people make it convenient to get to. We right off the subway line – City Hall is pretty central.
- RSVP. We did one thing wrong and one thing right. On the wrong side, we should have allowed more people to register recognizing that not everyone would show. We’d turned people away and ended up having room for them because of the no shows. On the right side, we blasted our list to see if anyone wasn’t going to come at the last minute and, got some responses, which allowed us to re-allocate those seats.
Engagement: Open Dataing

The one thing both Luke and I were committed to doing was getting participants and city staff to talk to one another. Building off an idea Luke witnessed in Ottawa we did 45 minutes of Open “Dataing.” During this period city staff from about eight different departments, as well as Minister Clement, staked out a part of the room. We then had people cluster – in groups of about 5-7 – around a department whose data or mission was of interest to them. They then had 10 minutes to learn about what data was available, ask questions about data they’d like, projects they were thinking of working on, or learn more about the operations of the city. In essence, they got to have a 10 minute speed date on data with a city official.
After 10 minutes blew a whistle and people went and clustered around a new official and did it all over again. It was a blast.
Key Lessons:
- Open Dataing is about getting everyone engaged. Helping public servants see what citizens are interested in and how they can see technology working for them, it’s also about getting participants to learn about what is available, what’s possible, and what are some of the real constraints faced by city staff
- I wish we’d had signs for the various departments being represented, would have made it easier for people to find and gravitate towards the issues that mattered most to them.
- This type of activity is great early on, it’s a way to get people talking and sharing ideas. In addition, we did the whole thing standing, that way no one could get too comfortable and it ensure that things kept flowing.
Outcomes
After the dating, we did a brief run through of projects people wanted to work on and basically stepped back and hacked. So what got worked on? There were other projects that were worked on, but here are the ones that saw presentations at the end of the day. There are some real gems.
Bike Parking App
The Bike Rack app came out of some challenges about data gathering that Councillor Reimer shared with me. I suggested the project and a team of students from UBC’s Magic Lab turned it into something real.
The city recently released a data set of the locations of all city owned bike racks. However, the city has little data about if these locations are useful. So the app that got hacked is very simple. When you arrive at your destination on bike you load it up and it searches for the nearest bike rack. For the user, this can be helpful. However, the app would also track that lat/long of where the search was conducted. This would let city planners know where people are when looking for bike rack so they would start to have some data about underserved locations. Very helpful. In addition, the app could have a crowdsourced function for marking the location of private bike racks (managed by businesses) as well as an option to lat/long where and when your bike was stolen. All this data could be used to help promote cycling, as well as help the city serve cyclists more effectively.
Homelessness Dashboard

My friend Luke connected a Raspberry Pi device to one of the giant TVs in the room where we were working to share the work he had done to create a dashboard based on the city’s rental standards database. Luke’s work even got featured on the Atlantic’s website.
Crime mapping – lots of quality questions
One great project involved no software at all. We had some real data crunchers in attendance and they started diving into the Vancouver Police Department’s data with a critical eye. I wish the VPD could have been there since their conclusions were not pretty. The truth is, the Vancouver Police department makes very little data open, and what it does make, is not very good. What was great to see were some very experienced statisticians explain why. I hope to be able to share the deck they created.
Air quality egg
A few weeks prior to Open Data Day I shared that I’d be launching a project – with the help of the Centre for Digital Media – around measuring air quality in Vancouver. Well, the air quality egg we’d ordered arrived and our team started exploring what it would, and might not, allow us to do. The results were very exciting. Open Data Day basically gave us time to determine that the technical hurdles we were worried about are surmountable – so we will be moving forward.
Over the coming months we’ll be crafting a website that uses Air Quality Eggs to measure the air quality in various neighborhoods in Vancouver. We have a number of other community partners that are hoping on board. By Clean Air Day we’d love to have 50-100 air quality eggs scattered across various neighborhoods in greater Vancouver. If you are interested in sponsoring one (they are about $150) please contact me.
Youth Oriented events RSS feed
One intrepid participant, also not a developer, got the city to agree to create and share an RSS feed of youth oriented events. This was important to them as they were concerned with youth issues – so a great example of a community organizer getting a data resource from the city. Next steps – trying to get other organizations with youth organized events to agree to share their program data in a similar data schema. What a great project.
Provincial Crowdsourced Road Kills and Poaching Maps
I was very excited to have to participants from the David Suzuki Foundation at the hackathon. They worked on creating some maps that would allow people to crowdsource map road kills, and instances of poaching, across the province of British Columbia. I love that they had a chance to explore the technical side of this problem, particularly as they may be well placed to resolve the community building side that would be essential to making a project like this a success.
Neighbourhood quality Heat Maps
Another team took various data sets from the Vancouver Open Data portal to generate heat maps of data quality (proximity to certain services and other variables). This prompted a robust conversation about the methodologies used to assess quality as well as how to account for services vs. population density. Exactly the types of conversations we want to foster!
Figuring our how to translate all of the data.vancouver.ca datasets
Another participant Jim DeLaHunt – put in some infrastructure that would make it easier to translate Vancouver’s open data into multiple languages in order to make it more accessible. He spent the day trying to identify what data in which data sets was structured versus unstructured human readable text. And… much to his credit he created a wiki page, the Vancouver Open Data language census to update people on his work so far.
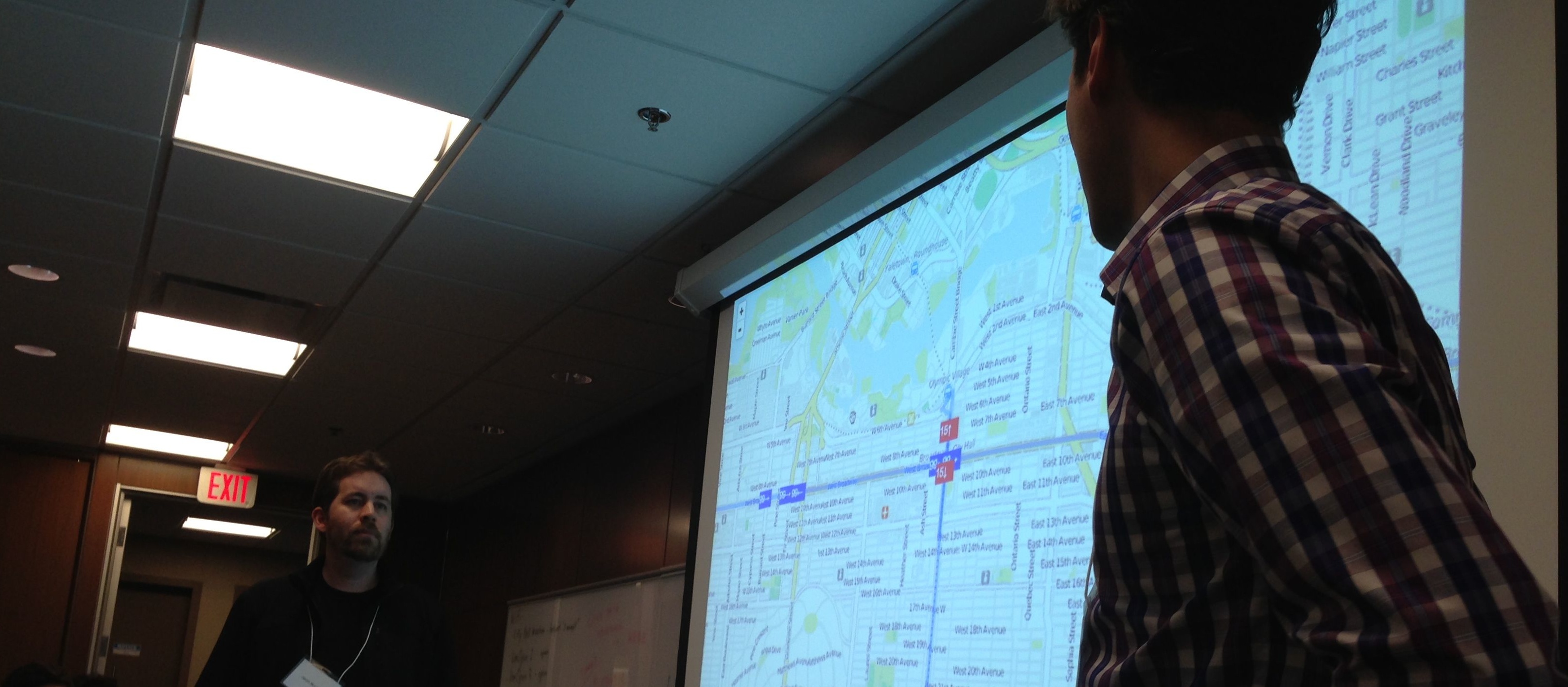
Live Bus Data Mapped

Another team played with the local transit authority’s real time bus data location API. It was pretty cool to see the dots moving across a google map in real time.
Their goals were mostly just to experiment, play and learn, but I know that apps like this have been sold into coffee shops in Boston, where they let customers know how far away the next bus.
Open Street Map
A Open Street Mapper participant spent the data getting address data merged with OSM.
Key Lessons:
- Don’t try to over manage the event – give people space and time to create
- Even if the energy feels low after a long day – definitely share out what people worked on, even if they didn’t finish what they wanted. There is lots to be learned from what others are doing and many new ideas get generated. It was also great for city staff to see what is possible
- Get people to share github repos and other links while on site. Too many of the above projects lack links!
Thank you again for everyone who made Open Data Day in Vancouver a success! Looking forward to next year!