While written for Mozilla, this piece really applies to any mission-driven organization. In addition, if you are media, please don’t claim this is written by Mozilla. I’m a contributor, and Mozilla is at its best when it encourages debate and discussion. This post says nothing about Mozilla official policy and I’m sure there Mozillians who will agree and disagree with me.
The Opportunity
Mozilla is an amazing organization. With a smaller staff, and aided by a community of supporters, it not only competes with the Goliaths of Silicon Valley but uses its leverage whenever possible to fight for users’ rights. This makes it simultaneously a world leading engineering firm and, for most who work there, a mission driven organization.
That was on full display this weekend at the Mozilla Summit, taking place concurrently in Brussels, Toronto and Santa Clara. Sadly, so was something else. A number of former Mozillians, many of whom have been critical to the organization and community were not participating. They either weren’t invited, or did not feel welcome. At times, it’s not hard to see why:
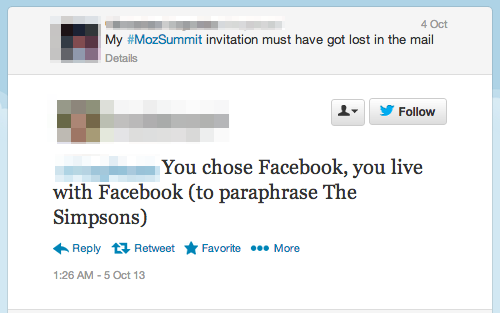
Again this is not an official Mozilla response. And that is part of the problem. There has never been much of an official or coordinated approach to dealing with former staff and community members. And it is a terrible, terrible lost opportunity – one that hinders Mozilla from advancing its mission in multiple ways.
The main reason is this: The values we Mozillians care about may be codified in the Mozilla Manifesto, but they don’t reside there. Nor do they reside in a browser, or even in an organization. They reside in us. Mozilla is about creating power by foster a community of people who believe in and advocate for an open web.
Critically, the more of us there are, the stronger we are. The more likely we will influence others. The more likely we will achieve our mission.
And power is precisely what many of our alumni have in spades. Given Mozilla’s success, its brand, and its global presence, Mozilla’s contributors (both staff and volunteers) are sought-after – from startups to the most influential companies on the web. This means there are Mozillians influencing decisions – often at the most senior levels – at companies that Mozilla wants to influence. Even if these Mozillians only injected 5% of what Mozilla stands for into their day-to-day lives, the web would still be a better place.
So it begs the question: What should Mozilla’s alumni strategy be? Presently, from what I have seen, Mozilla has no such strategy. Often, by accident or neglect, alumni are left feeling guilty about their choice. We let them – and sometimes prompt them to – cut their connections not just with Mozilla but (more importantly) with the personal connection they felt to the mission. This at a moment when they could be some of the most important contributors to our mission. To say nothing about continuing to contribute their expertise to coding, marketing or any number of other skills they may have.
As a community, we need to accept that as amazing as Mozilla (or any non-profit) is, most people will not spend their entire career there nor volunteer forever. Projects end. Challenges get old. New opportunities present themselves. And yes, people burn out on mission – which no longer means they don’t believe in it – they are just burned out. So let’s not alienate these people, let’s support them. They could be a killer advantage one of our most important advantages. (I mean, even McKinsey keeps an alumni group, and that is just so they can sell to them… we can offer so much more meaning than that. And they can offer us so much more than that).
How I would do it
At this point, I think it is too late to start a group and hope people will come. I could be wrong, but I suspect many feel – to varying degrees – alienated. We (Mozilla) will probably have to do more than just reach out a hand.
I would find three of the most respected, most senior Mozillians who have moved on and I’d reach out privately and personally. I’d invite them to lunch individually. And I’d apologize for not staying more connected with them. Maybe it is their fault, maybe it is ours. I don’t care. It’s in our interests to fix this, so let’s look inside ourselves and apologize for our contribution as a way to start down the path.
I’d then ask them if them if they would be willing to help oversee an alumni group. If they would reach out to their networks and, with us, bring these Mozillians back into the fold.
There is ample opportunity for such a group. They could be hosted once a year and be shown what Mozilla is up to and what it means for the companies they work for. They could open doors to C-suite offices. They could mentor emerging leaders in our community and they could ask for our advice as they build new products that will impact how people use the web. In short, they could be contributors.
Let’s get smart about cultivating our allies – even those embedded in organizations with don’t completely agree with. Let’s start thinking about how we tap into and help keep alive the values that made them Mozillians in the first place, and find ways to help them be effective in promoting them.