What is fascinating about this announcement and the recent changes at the bank is it appears to be very serious about open data and even more serious about open development. The repercussions of this shift, especially if the bank starts demanding that its national partners also disclose data, could be significant.
This of course, means there is lots to talk about. So, as part of the overall launch of the competition and in an effort to open up the workings of the World Bank, the organization hosted its first Open Forum in which a panel of guests talked about open development and open data. The bank was kind enough to invite me and so I ducted out of GTEC a pinch early and flew down to DC to meet some of the amazing people behind the world bank’s changes and discuss the future of open data and what it means for open development.
Embedded below is the video of the event.
As a little backgrounder here are some links to the bios of the different panelists and people who cycled through the event.
Our host: Molly Wood of CNET.
Andrew McLaughlin, Deputy Chief Technology Officer, The White House (formerly head of Global Public Policy and Government Affairs for Google) (twitter feed)
Stuart Gill, World Bank expert, Disaster Mitigation and Response for LAC
David Eaves, Open Government Writer and Activist
Rakesh Rajani, Founder, Twaweza, an initiative focused on transparency and accountability in East Africa (twitter)
Aleem Walji, Manager, Innovation Practice, World Bank Institute (twitter)
When I’m asked to give a talk about or consult on policies around open data I’ve noticed there are a few questions that are most frequently asked:
“How do I assess the risks to the government of doing open data?”
or
“My bosses say that we can only release data if we know people aren’t going to do anything wrong/embarrassing/illegal/bad with it”
I would argue that these question are either flawed in their logic, or have already been largely addressed.
Firstly, it seems problematic to assess the risks of open data, without also assessing the opportunity. Any activity – from walking out my front door to scaling Mount Everest carries with it risks. What needs to be measured are not the risks in isolation but the risks balanced against the opportunityand benefits.
But more importantly, the logic of the question is flawed in another manner. It suggests that the government only take action if every possible negative use can be prevented.
Let’s forget about data for a second – imagine you are building a road. Now ask: “what are the risk’s that someone might misuse this road?” Well… they are significant. People are going to speed and they are going to jay walk. But it gets worse. Someone may rob a bank and then use the road as part of their escaperoute. Of course, the road will also provide more efficient transportation for 1000s of people, it will reduce costs, improve access, help ambulances save peoples lives and do millions of other things, but people will also misuse it.
However, at no point in any policy discussion in any government has anyone said “we can’t build this road because, hypothetically, someone may speed or use it as an escape route during a robbery.”
And yet, this logic is frequently accepted, or at least goes unchallenged, as appropriate when discussing open data.
The fact is, most governments already have the necessary policy infrastructure for managing the overwhelming majority of risks concerning open data. Your government likely has provisions dealing with privacy – if applied to open data this should address these concerns. Your government likely has provisions for dealing with confidential and security related issues – if applied to open data this should address these concerns. Finally, your government(s) likely has a legal system that outlines what is, and is not legal – when it comes to the use of open data, this legal system is in effect.
If someone gets caught speeding, we have enforcement officials and laws that catch and punish them. The same is true with data. If someone uses it to do something illegal we already have a system in place for addressing that. This is how we manage the risk of misuse. It is seen as acceptable for every part of our life and every aspect of our society. Why not with open data too?
The opportunity, of both roads and data, are significant enough that we build them and share them despite the fact that a small number of people may not use them appropriately. Should we be concerned about those who will misuse them? Absolutely. But do we allow a small amount of misuse to stop us from building roads or sharing data? No. We mitigate the concern.
With open data, I’m happy to report that we already have the infrastructure in place to do just that.
For citizens of any city this is a fantastic primer on what open data is, why it matters and, in the case of Toronto, why it should be an election issue in the upcoming civic election.
Full disclosure: I did sit down with the paper’s authors at the Institute – Kimberly Silk and Jacqueline Whyte Appleby – to talk about a number of the critical aspects surrounding this issue. Their depth and experience in municipal and regional issues has produced an invaluable resource. I hope citizens of cities everywhere are able to make use of it, but I also hope that citizens of Toronto use it to ask questions of the candidates for Mayor and council.
For those not familiar with the Institute, you can read more about it here (excerpt below):
The Lloyd & Delphine Martin Prosperity Institute is the world’s leading think-tank on the role of sub-national factors – location, place and city-regions – in global economic prosperity. Led by Director Richard Florida , we take an integrated view of prosperity, looking beyond economic measures to include the importance of quality of place and the development of people’s creative potential.
If you run a large organization’s intranet site I encourage to read the piece. (Alternatively, if you are forced (or begged) to use one, forward this article to someone in charge). The measured results are great – essentially a doubling in pretty much all the things you want to double (like participation) – but what is really nice is how quick and affordable the whole project was, something rarely seen in most bureaucracies.
Here is an intranet for 30,000 employees, that “was rebuilt from top to bottom within 50 days with only three developers who were learning the open-source platform Drupal as they as went along.”
I beg someone in the BC government to produce an example of such a significant roleout being accomplished with so few resources. Indeed, it sounds eerily similar to GCPEDIA (available to 300,000 people using open source software and 1 FTE, plus some begged and borrowed resources) and OPSPedia (a test project also using open source software with tiny rollout costs). Notice a pattern?
Across our governments (not to mention a number of large conservative companies) there are tiny pockets where resourceful teams find a leader or project manager willing to buck the idea that a software implementations must be a multi-year, multimillion dollar roll out. And they are making the lives of public servants better. God knows our public servants need better tools, and quickly. Even the set of tools being offered in the BC examples weren’t that mind-blowing, pretty basic stuff for anyone operating as a knowledge worker.
I’m not even saying that what you do has to be open source (although clearly, the above examples show that it can allow one to move speedily and cheaply) but I suspect that the number of people (and the type of person) interested in government would shift quickly if, internally, they had this set of tools at their disposal. (Would love to talk to someone at Canada’s Food Inspection Agency about their experience with Socialtext)
The fact is, you can. And, of course, this quickly get us to the real problem… most governments and large corporations don’t know how to deal with the cultural and power implications of these tools.
We’ll we’d better get busy experimenting and trying cause knowledge workers will go where they can use their and their peers brains most effectively. Increasingly, that isn’t government. I know I’m a fan of the long tail of public policy, but we’ve got to fix government behind the firewall, otherwise their won’t be a government behind the firewall to fix.
Since the resignation of Deputy Minister Munir Sheikh and his public repudiation of voluntary long form census it has become clear that Industry Minister Clement has – at best – been misleading the public about the advice he received from statscan.
For instance, the real 2006 census long-form found that renting households as a percentage of the population in Canada had dropped by 3.08 percentage points from the 2001 census.
But when the Statscan study simulated the results of a voluntary 2006 long-form – which reflect the lower response rates expected in optional surveys – it got a markedly different answer. Calculations instead indicated that rented dwellings in Canada as a share of the population declined by 8.07 percentage points from 2001.
The difference – nearly five percentage points – suggests a voluntary survey in 2006 would have massively undercounted renting households.
So a mere 150% difference. Which, of course, might affect how every city in Canada considered zoning issues and adjust policies around the housing and rentals stock.
Again, if the Government wants to scrap the long-form census, that’s their prerogative. And I suppose we can’t be surprised that a government that wants less data and information to inform decisions would ignore data that showed them the negative consequence of their proposal. I mean, when you’ve already decided evidence doesn’t matter in crime policy, health policy and a myriad of other issues, you aren’t suddenly going to decide the collecting evidence is important…
But if that is your conclusion, stick with it! Don’t lie to me and the Canadian public and claim it won’t have a dramatic impact on the quality of data the Government collects or an impact on how policy and services for Canadians are affected.
And, of course, given how sensitive the decision is, and how it will cascade down and impact businesses, non-profits, local, provincial and federal government decision making, I wish we’d had a chance to debate the merits of it before the decision was made. Who knows, such a debate might not have just saved the long form census, it might have save government a 10-point decline in the polls.
My 5 minute lightening fast jam packed talk (do I do other formats? answer… yes) from yesterday’s Gov2.0 summithasn’t yet been has just been posted to youtube. I love that this year the videos have the slides integrated into it.
For those who were, and were not, there yesterday, I wanted to share links to all the great sites and organizations I cited during my talk, I also wanted to share one or two quick stories I didn’t have time to dive into:
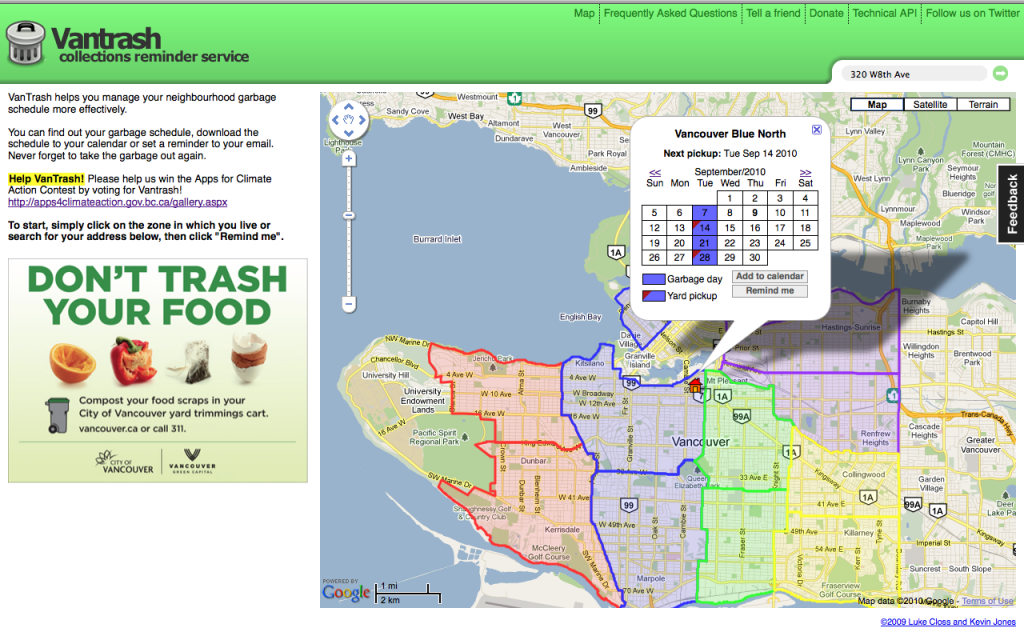
VanTrash and 311:
As one of the more mature apps in Vancouver using open data Vantrash keeps being showing us how these types of innovations just keep giving back in new and interesting ways.
In addition to being used by over 3000 households (despite never being advertised – this is all word of mouth) it turns out that the city staff are also finding a use for vantrash.
I was recently told that 311 call staff use Vantrash to help trouble shoot incoming calls from residents who are having problems with garbage collection. The first thing one needs to do in such a situation is identify which collection zone the caller lives in – turns out VanTrash is the fastest and more effective way to accomplish this. Simply input the caller’s address into the top right hand field and presto – you know their zone and schedule. Much better than trying to find their address on a physical map that you may or may not have near your station.
TaxiCity, Open Data and Game Development
Another interesting spin off of open data. The TaxiCity development team, which recreated downtown Vancouver in 2-D using data from the open data catalog, noted that creating virtual cities in games could be a lot easier with open data. You could simply randomize the height of buildings and presto an instant virtual city would be ready. While the buildings would still need to be skinned one could recreate cities people know quickly or create fake cities that felt realistic as they’d be based on real plans. More importantly, this process could help reduce the time and resources needed to create virtual cities in games – an innovation that may be of interest to those in the video game industry. Of course, given that Vancouver is a hub for video game development, it is exactly these types of innovations the city wishes to foster and will help sustain Vancouver’s competitive advantage.
Links (in order of appearance in my talk)
Code For America shirt design can be seen in all their glory here and can be ordered here. As a fun aside, I literally took that shirt of Tim O’Reilly’s back! I saw it the day before and said, I’d wear that on stage. Tim overheard me and said he’d give me his if I was serious…
Vancouver’s Open Data Portal is here. keep an eye on this page as new data sets and features are added. You can get RSS feed or email updates on the page, as well as see its update history.
Vantrash the garbage reminder service’s website is here. There’s a distinct mobile interface if you are using your phone to browse.
TaxiCity, the Centre for Digital Media Project sponsored by Bing and Microsoft has its project page here. Links to the sourcecode, documentation, and a ton of other content is also available. Really proud of these guys.
Microsoft’s Internal Vancouver Open Data Challenge fostered a number of apps. Most have been opensourced and so you can get access to the code as well. The apps include:
The Graffiti Analysis written by University of British Columbia undergraduate students can be downloaded from this blog post I posted about their project.
BTA Works – the research arm of Bing Thom Architects has a great website here. You can’t download their report about the future of Vancouver yet (it is still being peer-reviewed) but you can read about it in this local newspaper article.
Long Tail of Public Policy – I talk about this idea in some detail in my chapter on O’Reilly Media’s Open Government. There is also a brief blog post and slide from my blog here.
Vancouver’s Open Data License – is here. Edmonton, Ottawa and Toronto use essentially the exact same thing. Lots that could be done on this front still mind you… Indeed, getting all these cities on a single standard license should be a priority.
Vancouver Data Discussion Group is here. You need to sign in to join but it is open to anyone.
One promise of open data is its ability to inform citizens and consumers about the quality of local services. At the Gov 2.0 Summit yesterday the US Department of Health and Human Resources announced it was releasing data on hospitals, nursing homes and clinics in the hopes that developers will create applications that show citizens and consumers how their local hospitals stacks up against others. In short, how good, or even how safe, is their local hospital?
In Canada we already have some experience with this type of measuring. The Fraser Institute publishes an annual report card of schools performance in Alberta, BC, Ontario and Washington. (For those unfamiliar with the Fraser Institute it is a right-wing think tank based in Vancouver with, shall we say, dubious research credentials but strong ideological and fundraising goals.
Perhaps unsurprisingly, private schools do rather well in the Fraser Institute’s report card. Indeed it would appear (and I may be off by one here) that the t0p 18 schools on the list are all private. This does support a narrative that private schools are inherently better than state run schools that would be consistent with the Fraser Institute’s outlook. But, of course, that would be a difficult conclusion to sustain. Private schools tend to be populated with kids from wealthy families with better educated parents and have been given a blessed head start in life. Also, and not noted in the report card, is that many private schools are comfortable turfing out under-performing or unruly students. This means that the “delayed advancement rate,” one critical metric of a schools performance, is dramatically less impacted than a public school that cannot as easily send students packing.
Indeed, the Fraser Institute’s report card is rife with problems, something that teachers unions and, say, equally ideological but left-oriented think tanks like the Centre for Policy Alternatives are all too happy to point out.
While I loath the Fraser Institute’s simplistic report card and think it is of dubious value to parents I do like that they are at least trying to give parents some tool by which to measure schools. The notion that schools, teachers and education quality can’t be measured, or are too complicated to measure is untenable. I suspect few parent – especially those in say, jobs where they are evaluated – believe it. Nor does such a position help parents assess the quality of education their child is receiving. While they understand, may be sympathetic to or even agree that this is a complicated issue it seems clear based on the success of Ontario’s school locator that many parents want and like these tools.
Ultimately the problem here isn’t the open data (despite what critics of the Ontario Government’s school comparison website would have you believe). Besides, are we now going to hide or suppress data so that parents can’t assess their kids schools? Nor is the problem school report cards per se. If anything is the problem it is that the Fraser Institute has had the field all to itself to play in. If teachers groups, other think tanks, or any other group believes that the Fraser Institute’s report cards are not too crude, why not design a better one? The data is available (and the government could easily be pressured to make more of it available). Why don’t teacher’s groups share with parents the metrics by which they believe parents should evaluate and compare schools? What this issue could use is some healthy competition and debate – one that generated more options and tools for parents.
The challenge for government is to make data more easily available. By making educational data more accessible, less time, IT skills and energy is needed to organize the data and precious resources can instead be focused on developing and visualizing the scoring methodology. This is certainly seems to be Health and Human Services approach: lower transaction costs, galvanize a variety of assessment applications and foster a healthy debate. It would be nice if ministries of education in Canada took a similar view.
But the second half of that challenge is also important, and groups outside of government need to recognize they can have a role, and the consequence of not participating. The mistake is to ask how to deal with groups like the Fraser Institute that use crude metrics, instead we need to encourage more groups and encourage our own organizations to contribute to the debate, to give it more nuance, and create better tools. Leaving the field to the Fraser Institute is a dangerous strategy, one that will serve few people. This is even more the case since in the future we are likely to have more, not less data about education, health and a myriad of other services and programs.
So, the challenge for readers is – will your organization participate?
Sorry for the lack of posts this week, blog was offline for a bit. (For geeks out there, I now have a company managing my blog for me and we we’re moving from a shared hosting service to a virtual private server – I should have less down time in the future – very excited).
Sadly, in that time there have been a bunch of fascinating developments on the census. As some of you may be aware a new poll by EKOS emerged today that has the Liberals and Conservatives dead even. More interesting however is how the census is playing a key role in the shift:
In seeking an explanation for these movements, we need look no further than the government’s ill-received decision to end the mandatory long form census. Not only does the shift of the highly educated support this conclusion, but a direct question on public approval for this decision provides compelling evidence that this move precipitated the current woes that the Conservative Party now faces.
When asked whether they felt that the privacy intrusion of the census justified a voluntary census or whether the lack of representativeness would cost us vital data, a clear majority of the public (56%) picked the latter (compared 26% who felt the mandatory long form was a violation of privacy). Even among Tory supporters, this appeal is not selling and there is an overwhelming lean to disapproval in the rest of the spectrum. Opposition to this decision is strongest among the university educated.
Of course, one of the retorts from pundits in favour of scrapping the long form census has been that only a few people care about this issue, it won’t matter in the medium term and it certainly won’t impact any election. For example:
Two things: I still standby my thesis that I believe that chucking mandatory nature of the long-form is a move to dismantle the welfare state (and that this is a move in the right direction). And two, nobody cares outside of the beehive. It’s the media that is pushing the story outside of the beehive walls propelled by the loud buzz of special interests.
Sigh, I suppose that 56% of Canadians represent “a special interest.”
For me, both groups (56% and 26%) have legitimate concerns. As such, efforts by those in favour of this decision opposition as “special interest” driven are wrong and, frankly, disingenuous. Happily, they have failed. Indeed, the more these pundits try, the more they seem to make this a wedge issue in favour of those opposed to the decision. Mostly, I just think it would have been nice to have the issue debated before a decision was made.
More interesting has been another effort to defend trashing the long form census. I think Jack Mintz has thoroughly damaged his credibility with a terrible, contradictory and misleading op-ed in the Financial Post. Rather than dive into it, I encourage everyone to wander over to Aaron Wherry’s fantastic (and, unlike this post, short) dismantling of it. He’s already done all the heavy lifting.
Finally, just because I could help but notice the irony… I see that Conservative MP Garry Breitkreuz has an oped in the Mark in which he is worried about the role that the police is taking lobbying to keep the registry alive:
Taxpayers should be incensed at the CACP for co-opting the role of policy-maker. When law enforcement managers try to write the laws they enforce, history has taught us we risk becoming a state where police can dictate our personal freedoms.
But on further review, maybe we shouldn’t get to excited. Looking at Garry’s website, and specifically, this PDF he’s made available for download, it seems like he’s actually quite keen to have police force members be outspoken about the gun registry as long as they agree with his view.
The other week – in the midst of boarding a plane(!) – I did an interview with the CSEDEV on some thoughts around open data, open government and open source.
The kind people at CSEDEV have written up the interview in a kind of paraphrased way and published it as three short blog posts here, part 2 here and part 3 here.
Part of what makes this interesting to me is how a broader set of people are becoming interested in open government. Take CSEDEV for example. Here is an Ottawa based software firm focused on enterprise solutions. It’s part of an increasing number of software companies and IT consulting firms are taking note of the open government and open data meme. Indeed, another concrete example of this is Lagan, a large supplier of 311 systems, announced the other week that they would support the open311 standard. This dramatically alters the benefits of a 311 system and the capacity for it to serve as a platform and innovation driver for a city.
But, even more exciting, the meme is starting to spread beyond IT and software. I was recently asked to write an article on what open data and open government means for business more generally, here in BC. (Will link to it, when published)
These moments represent an important shift in the open data and open government debate. With vendors and consultants taking notice governments can more easily push for, and expect, off the shelf solutions that support open government initiatives. Not only could this reduce cost to government and improve access for public servants and citizens, it could also be a huge boost for open standards which prove to be transformative to the management of information in the public sector.
Exciting times. Watch the open government space – now that it’s linked to IT, it’s beginning to gain speed.
Here’s a few snippets of comments, emails and other communications I’ve had this week in response to specific posts or just the blog in general. Each one touches on why I love blogging and my readers and why this blog has come to mean so much to me.
Venting, and finding out your not alone…
So, yesterday I got a little bit into a hate-on for Statistics Canada’s website. It wasn’t the first time and pretty much every time I do it I find another soul out there whose had their soul crushed by the website as well. Take this comment from last week:
Re: Stats Canada’s website being unusable. I completely frickin agree. God. Has anyone in government actually tried to use that website? An econ professor gave our class an assigment last year that involved looking stuff up on Statscan. Half of our class failed the assignment because they gave up and the other half had the wrong data, but got the marks anyways for trying. I think he actually took that assigment off of the grading at the end. It’s a bloody gong show…
Sometimes it makes me feel more human knowing that others are out there struggling with the same thing. StatsCan does great work… I just wish they made it accessible.
…and then having some kind souls find some solutions for you.
But as nice as knowing you’re not alone… even better is how often the internet connects you to others who just happen to have that esoteric piece of knowledge that saves the day.
I agree, Stats Can is one of the worst government websites out there (specifically those stupid CANSIM tables), one that, as a policy analyst with XXXXXXXX Canada, i frequently have to use to get data. I had the data for XXXXXXX and it wasn’t hard to get it for the country.
This kind soul led me straight to a completely different page on statscan that happened to have the data I was looking for. (for those interested, it was here).
And they weren’t the only one. Another reader posted a link to the data over twitter…
Thank god there is an army good natured amateur and professional experts experienced in navigating the byzantine structure of the statscan website!
So… thank you! I’m going to try to grind out an updated pan-North American version of the Fatness Index this weekend.
Impacting Policy
But this week also had that other rewarding ingredient I love to get: hearing about a post helped, incrementally, foster better public policy. This came in via email from a public servant about yesterday’s blog post:
Your blog today provided a good example in a meeting with government colleagues about the benefits of opening data. It illustrates the implications of not releasing data to the public (e.g. stifling innovation)… It resonated well with them.
This is a huge part of why I blog. Part of it is to explore ideas, part of it is to introduce ideas and thoughts, but a big piece of it is to enable public servants and do just this, helps small internal government meeting (on subjects like open data) go a little more smoothly.
So to everyone out there, be it policy wonks, students, public servants, politicians or ordinary, engaged citizens. Thank you. It was a good week. We wrote some good posts, some good comments, had an original story on the stupidity of the census, and maintained sanity in the face of the StatsCan website. Thank you everyone for making it so fun. Hope you all have a great weekend. – Dave