This week, I’m pleased to announce the beta launch of Emitter.ca – a website for locating, exploring and assessing pollution in your community.
Why Emitter?
A few weeks ago, Nik Garkusha, Microsoft’s Open Source Strategy Lead and an open data advocate asked me: “are there any cool apps you could imagine developing using Canadian federal government open data?”
Having looked over the slim pickings of open federal data sets – most of which I saw while linking to them datadotgc.ca – I remembered one: Environment Canada’s National Pollutant Release Inventory (NPRI) that had real potential.
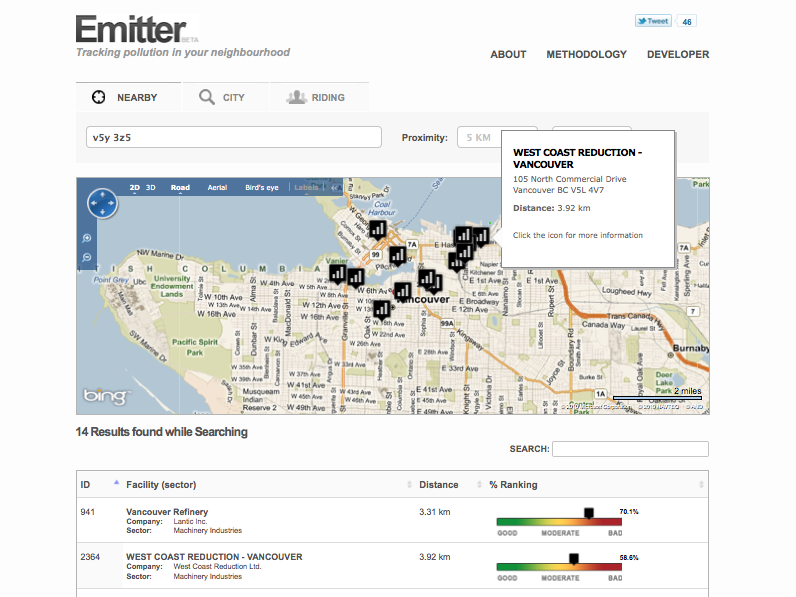
With NPRI I felt we could build an application that allowed people and communities to more clearly see who is polluting, and how much, in their communities could be quite powerful. A 220 chemicals that NPRI tracks isn’t, on its own, a helpful or useful to most Canadians.
We agreed to do something and set for ourselves three goals:
- Create a powerful demonstration of how Canadian Federal open data can be used
- Develop an application that makes data accessible and engaging to everyday Canadians and provides communities with a tool to better understand their immediate region or city
- Be open
With the help of a crew of volunteers with knew and who joined us along the way – Matthew Dance (Edmonton), Aaron McGowan (London, ON), Barranger Ridler (Toronto) and Mark Arteaga (Oakville) – Emitter began to come together.
Why a Beta?
For a few reasons.
- There are still bugs, we’d love to hear about them. Let us know.
- We’d like to refine our methodology. It would be great to have a methodology that was more sensitive to chemical types, combinations and other factors… Indeed, I know Matt would love to work with ENGOs or academics who might be able to help provide us with better score cards that can helps Canadians understand what the pollution near them means.
- More features – I’d love to be able to include more datasets… like data on where tumours or asthama rates or even employment rates.
- I’d LOVE to do mobile, to be able to show pollution data on a mobile app and even in using augmented reality.
- Trends… once we get 2009 and/or earlier data we could begin to show trends in pollution rates by facility
- plus much, much more…
Build on our work
Finally, we have made everything we’ve done open, our methodology is transparent, and anyone can access the data we used through an API that we share. Also, you can learn more about Emitter and how it came to be reading blog posts by the various developers involved.
- Mark Arteaga gives an overview of the project
- Nik writes about the technology behind emitter.
- Aaron talks about working with ODGI from a developers perspective and a more general blog post
- Barranger Ridler talks about loading data to ODGI
Thank yous
Obviously the amazing group of people who made Emitter possible deserve an enormous thank you. I’d also like to thank the Open Lab at Microsoft Canada for contributing the resources that made this possible. We should also thank those who allowed us to build on their work, including Cory Horner’s Howdtheyvote.ca API for Electoral District boundaries we were able to use (why Elections Canada doesn’t offer this is beyond me and, frankly, is an embarrassment). Finally, it is important to acknowledge and thank the good people at Environment Canada who not only collected this data, but have the foresight and wisdom to share make it open. I hope we’ll see more of this.
In Sum
Will Emitter change the world? It’s hard to imagine. But hopefully it is a powerful example of what can happen when governments make their data open. That people will take that data and make it accessible in new and engaging ways.
I hope you’ll give it a spin and I look forward to sharing new features as they come out.
Update!
Since Yesterday Emitter.ca has picked up some media. Here are some of the links so far…
Hanneke Brooymans of the Edmonton Journal wrote this piece which was in turn picked up by the Ottawa Citizen, Calgary Herald, Canada.com, Leader Post, The Province, Times Columnist and Windsor Star.
Nestor Arellano of ITBusiness.ca wrote this piece
Burke Campbell, a freelance writer, wrote this piece on his site.
Kate Dubinski of the London Free Press writes a piece titled It’s Easy to Dig up Dirt Online about emitter.ca

