So let me start by saying, in theory, I LOVE Car2Go. The service has helped prevent me from buying a car and has been indispensable in opening up more of Vancouver to me.
For those not familiar with Car2Go, it is a car sharing service where the cars can be parked virtually anywhere in the city, so when you need one, you just use a special card and pin number to access it, drive it to where you want to go and then log out of the car leaving it for the next person to use it. All this at the affordable rate of 38 cents a minute. It’s genius.
So what’s the problem?
Well, in practice, I’m having an increasingly worse experience with Car2Go, particularly when I’m most in need the service. What’s worse, the reasons are entirely within the control of Car2Go and specifically how it designed its app, its workflow and its security. My hope is there are lessons here for designers and anyone who is thinking about online services, particularly in the mobile space.
Let me explain.
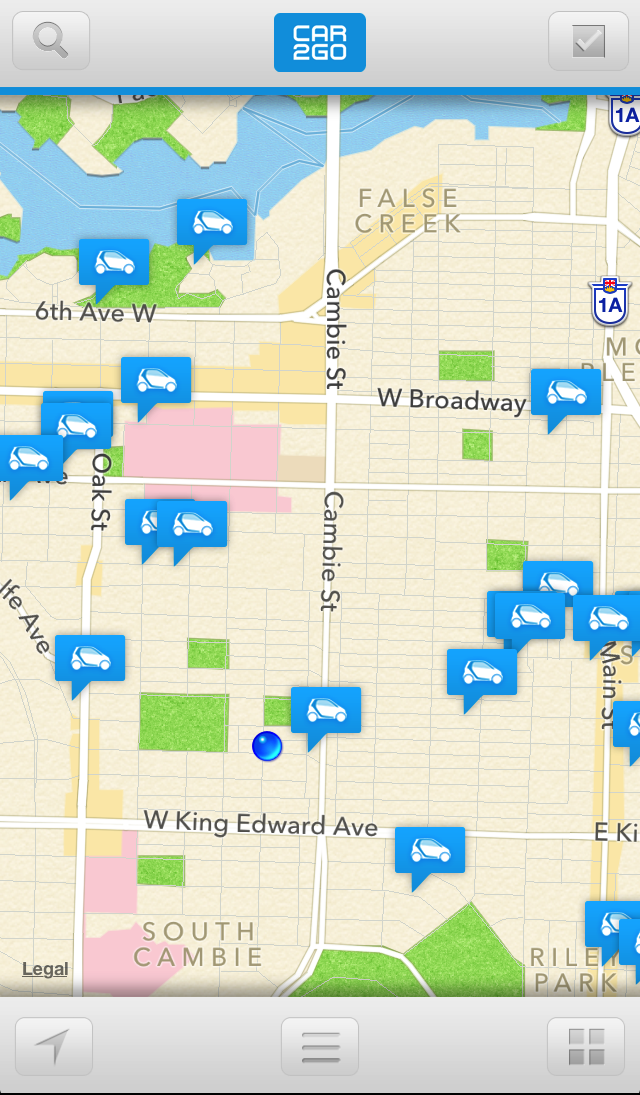 First, understand that the Car2Go’s brand is built around convenience. Remember, the use case is that, at almost any time, you can find a car near you, access it, and get to where you want to go. Car2Go is not for people planning to use a car hours ahead (you don’t really want to be paying 38 cents a minute to “hold” a car for 3 hours until you need it. That would cost you $68!). Indeed the price point is designed to discourage long term use and encourage short, convenient trips. As a result ease of access is central to the service and the brand promise.
First, understand that the Car2Go’s brand is built around convenience. Remember, the use case is that, at almost any time, you can find a car near you, access it, and get to where you want to go. Car2Go is not for people planning to use a car hours ahead (you don’t really want to be paying 38 cents a minute to “hold” a car for 3 hours until you need it. That would cost you $68!). Indeed the price point is designed to discourage long term use and encourage short, convenient trips. As a result ease of access is central to the service and the brand promise.
In theory here is what the process should look like.
- Fire up the Car2Go app on your smart phone and geolocate yourself
- Locate the nearest car (see screen shot to right)
- Reserve it (this allows you to lock the car down for 15 minutes)
- Walk to your car, access it using your Car2Go card and pin number
- Drive off!
Here is the problem. The process now regularly breaks down for me at step 3. At first blush, this may not seem like a big deal… I mean, if the car is only a few blocks away why not just walk over and grab it?
Alas, I do. But, often when you really want a car someone else does too! This is even more the case when say… it’s raining, or it’s the end of the business day. Indeed, many of the times when you would really like that car are times when someone else might also really want it. So being able to lock it down is important. Because if you can’t…? Well, the other week I walked 12 blocks in the rain trying to get to 4 different Car2Go cars that I could see in the app but couldn’t reserve. Why four? Because by the time I got each of them, they were gone, scooped by another suer. After 30 minutes of walking around and getting wet, I gave up, abandoned my appointment (very suboptimal) and went home. This is not the first time this has happened.
The impact is that Car2Go is increasingly not a service I see myself relying on. Yes, I keep using it, but I no longer think of it as a service I can count on if I just cushion a little extra time. It’s just… kind of reliable because the split between really frustrating outcome and totally delight, is starting to be 40/60, and that’s not good.
 But here is the killer part. Car2Go could fix this problem in a day. Tops.
But here is the killer part. Car2Go could fix this problem in a day. Tops.
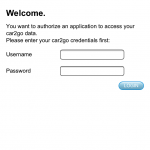
The reason I can’t reserve a car is a because the Car2Go app forces you to log back in every once and a while. Why? I don’t know. Even if someone stole my phone and used it to reserve a car it would be useless. Let’s say they managed to also steal my wallet so had my Car2Go card. Even now it doesn’t help them since without my pin they couldn’t turn the car on. So having some rogue person with access to user’s account isn’t exactly putting Car2Go in any danger.
So maybe you’re thinking… well, just remember your password David! So here’s a big user moment.
I WISH I COULD.
But Car2Go has these insanely stupid, deeply unsafe password rules that require you to have at least one number, one letter and a capitalized letter (or a special character – god knows if I remember their rules) in your password. Since the multitude of default passwords I use don’t conform to their rules, I can never remember what my password is, leaving me locked out of my Car2Go app. And trust me, when you are late for a meeting, it’s raining and you’re getting soaked, the last thing you want to be doing is going through a password reset process on webpages built for desktop browsers that takes 10 t0 15 minutes to navigate and complete. Many a curse word has been directed at Car2Go in such moments.
What’s worse is there is evidence that shows that not only do these passwords rules create super crappy user experiences like the one I described above, they also user accounts less secure. Indeed, check out this Wired article on passwords and the tension between convenience and effectiveness:
Security specialists – and many websites – prompt us to use a combination of letters, numbers, and characters when selecting passwords. This results in suggestions to use passwords like “Pn3L!x8@H”, to cite a recent Wired article. But sorry, guys, you’re wrong: Unless that kind of password has some profound meaning for a user (and then he or she may need other help than password help), then guess what? We. Will. Forget. It.
It gets worse. Because you will you forget it, you’ll do something both logical and stupid. YOU’LL WRITE IT DOWN. Probably somewhere that will be easy to access. LIKE IN YOUR PHONE’S ADDRESS BOOK.
Stupid password rules don’t make users create smarter passwords. It makes them do dumb things that often make their accounts less secure.
The result? Car2Go’s design and workflow creates a process that suboptimizes the user experience, all in an effort to (I’m guessing) foster security but that, in reality, likely causes a number of Car2Go users to make terrible decisions and make their accounts more vulnerable.
So if you are creating an online service, I hope this cautionary tale about design, workflow is helpful and password authentication rules. Get them wrong and you can really screw up your product.
So please, don’t do to your service what Car2Go has done to theirs. As a potential user of your product, that would make me sad.