A few hours ago, Vancouver’s city government posted the agenda to a council meeting next week in which this motion will be read:
MOTION ON NOTICE
Open Data, Open Standards and Open Source
MOVER: Councillor Andrea Reimer
SECONDER: CouncillorWHEREAS the City of Vancouver is committed to bringing the community into City Hall by engaging citizens, and soliciting their ideas, input and creative energy;
WHEREAS municipalities across Canada have an opportunity to dramatically lower their costs by collectively sharing and supporting software they use and create;
WHEREAS the total value of public data is maximized when provided for free or where necessary only a minimal cost of distribution;
WHEREAS when data is shared freely, citizens are enabled to use and re-purpose it to help create a more economically vibrant and environmentally sustainable city;
WHEREAS Vancouver needs to look for opportunities for creating economic activity and partnership with the creative tech sector;
WHEREAS the adoption of open standards improves transparency, access to city information by citizens and businesses and improved coordination and efficiencies across municipal boundaries and with federal and provincial partners;
WHEREAS the Integrated Cadastral Information Society (ICIS) is a not-for-profit society created as a partnership between local government, provincial government and major utility companies in British Columbia to share and integrate spatial data to which 94% of BC local governments are members but Vancouver is not;
WHEREAS digital innovation can enhance citizen communications, support the brand of the city as creative and innovative, improve service delivery, support citizens to self-organize and solve their own problems, and create a stronger sense of civic engagement, community, and pride;
WHEREAS the City of Vancouver has incredible resources of data and information, and has recently been awarded the Best City Archive of the World.
THEREFORE BE IT RESOLVED THAT the City of Vancouver endorses the principles of:
- Open and Accessible Data – the City of Vancouver will freely share with citizens, businesses and other jurisdictions the greatest amount of data possible while respecting privacy and security concerns;
- Open Standards – the City of Vancouver will move as quickly as possible to adopt prevailing open standards for data, documents, maps, and other formats of media;
- Open Source Software – the City of Vancouver, when replacing existing software or considering new applications, will place open source software on an equal footing with commercial systems during procurement cycles; and
BE IT FURTHER RESOLVED THAT in pursuit of open data the City of Vancouver will:
- Identify immediate opportunities to distribute more of its data;
- Index, publish and syndicate its data to the internet using prevailing open standards, interfaces and formats;
- Develop appropriate agreements to share its data with the Integrated Cadastral Information Society (ICIS) and encourage the ICIS to in turn share its data with the public at large
- Develop a plan to digitize and freely distribute suitable archival data to the public;
- Ensure that data supplied to the City by third parties (developers, contractors, consultants) are unlicensed, in a prevailing open standard format, and not copyrighted except if otherwise prevented by legal considerations;
- License any software applications developed by the City of Vancouver such that they may be used by other municipalities, businesses, and the public without restriction.
BE IT FINALLY RESOLVED THAT the City Manager be tasked with developing an action plan for implementation of the above.
A number of us having been working hard getting this motion into place. While several cities, like Portland, Washington DC, and Toronto, have pursued some of the ideas outlined in this motion, none have codified or been as comprehensive and explicit in their intention.
I certainly see this motion as the cornerstone to transforming Vancouver into a open city, or as my friend Surman puts it, a city that thinks like the web.
At a high level, the goal behind this motion is to enable citizens to create, grow and control the virtual manifestation of their city so that they can in turn better influence the real physical city.
In practice, I believe this motion will foster several outcomes, including:
1. New services and applications: That as data is opened up, shared and has APIs published for it, our citizen coders will create web based applications that will make their lives – and the lives of other citizens – easier, more efficient, and more pleasant.
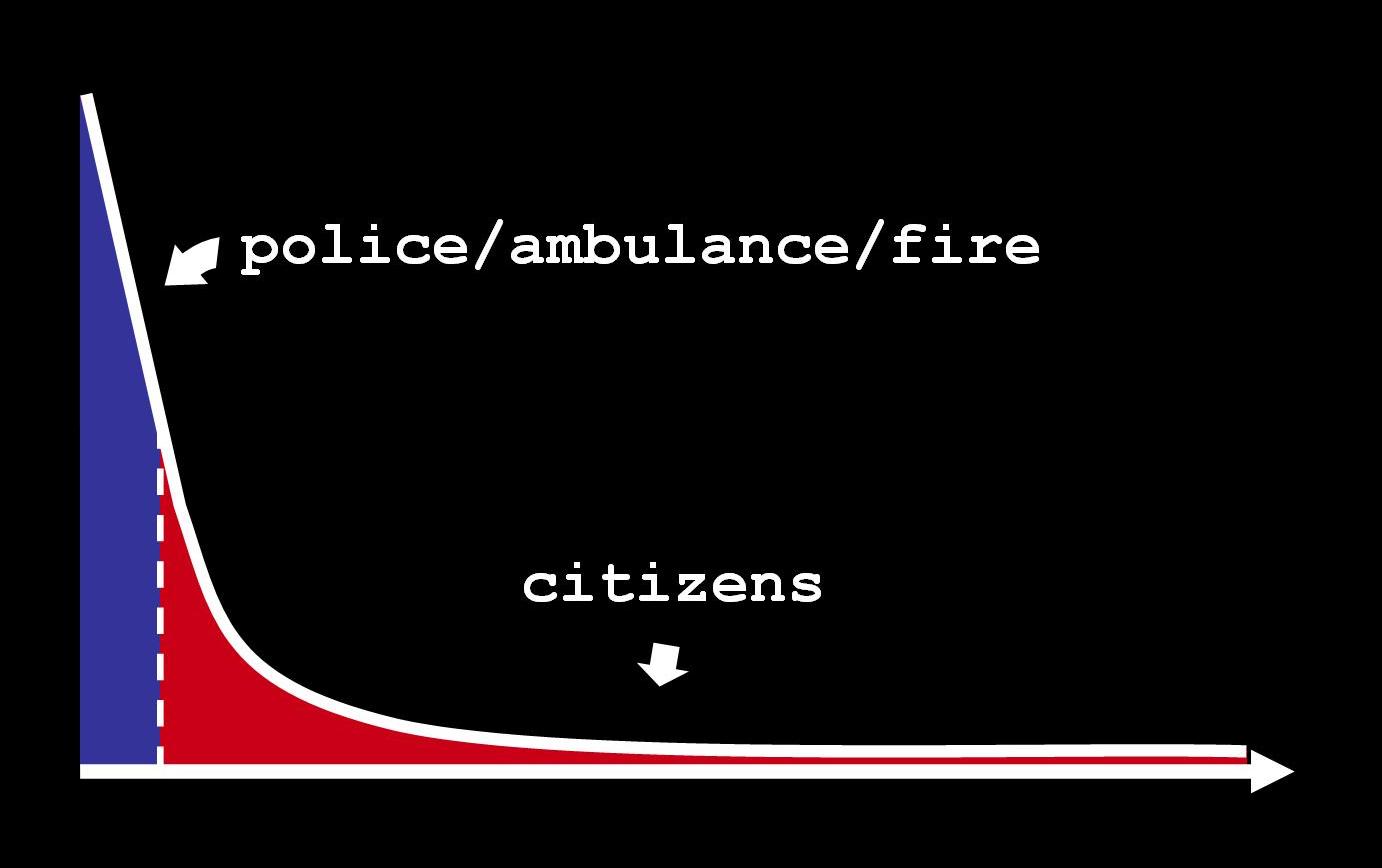
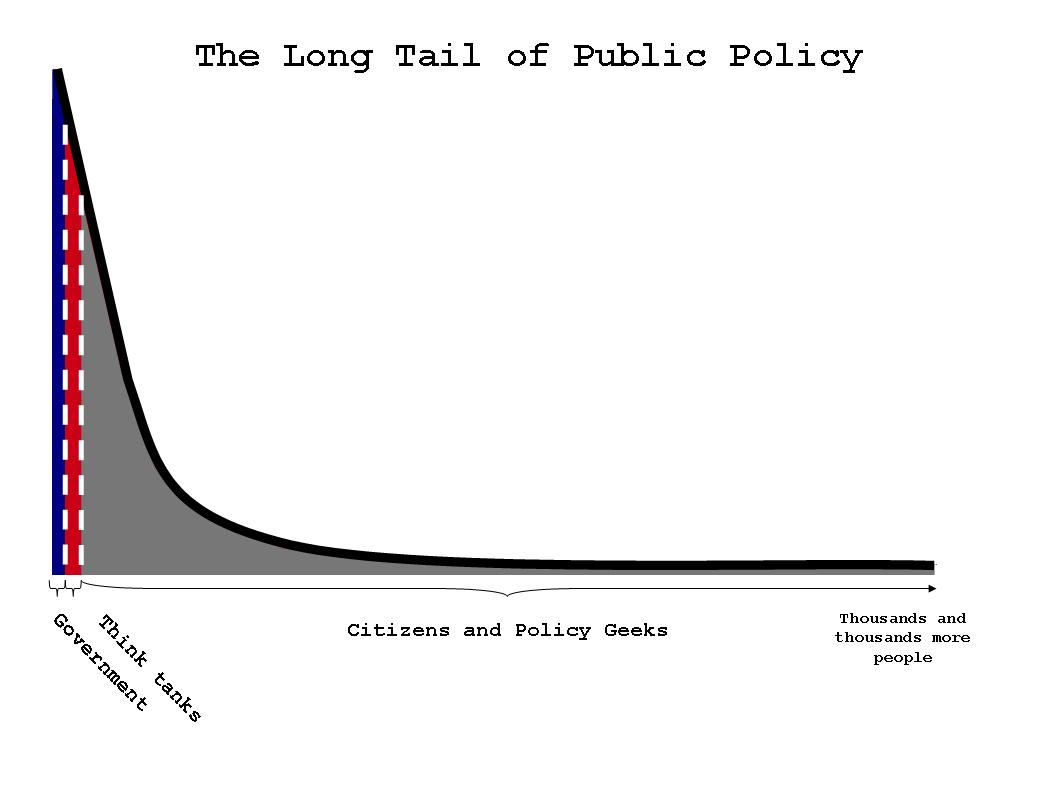
2. Tapping into the long tail of public policy analysis: As more and more Vancouverites look over the city’s data, maps and other pieces of information citizens will notice inefficiencies, problems and other issues that could save money, improve services and generally make for a stronger better city.
3. Create new businesses and attract talent: As the city shares more data and uses more open source software new businesses that create services out of this data and that support this software will spring up. More generally, I think this motion, over time could attract talent to Vancouver. Paul Graham once said that great programmers want great tools and interesting challenges. We are giving them both. The challenge of improving the community in which they live and the tools and data to help make it better.
For those interested in appearing before City Council to support this motion, details can be found here. The council meeting is this Tuesday, May 19th at 2pm, PST. You can also watch the proceedings live.
For those interested in writing a letter in support of the motion, send your letter here.