Last week I gave a talk at the Conference for Parliamentarians hosted by the Information Commission as part of Right to Know Week.
During the panel I noted that, if we are interested in improving response times for Freedom of Information (FOI) requests (or, in Canada, Access to Information (ATIP) requests) why doesn’t the Office of the Information Commissioner use a bugzilla type software to track requests?
Such a system would have a number of serious advantages, including:
- Requests would be public (although the identity of the requester could remain anonymous), this means if numerous people request the same document they could bandwagon onto a single request
- Requests would be searchable – this would make it easier to find documents already released and requests already completed
- You could track performance in real time – you could see how quickly different ministries, individuals, groups, etc… respond to FOI/ATIP requests, you could even sort performance by keywords, requester or time of the year
- You could see who specifically is holding up a request
In short such a system would bring a lot of transparency to the process itself and, I suspect, would provide a powerful incentive for ministries and individuals to improve their performance in responding to requests.
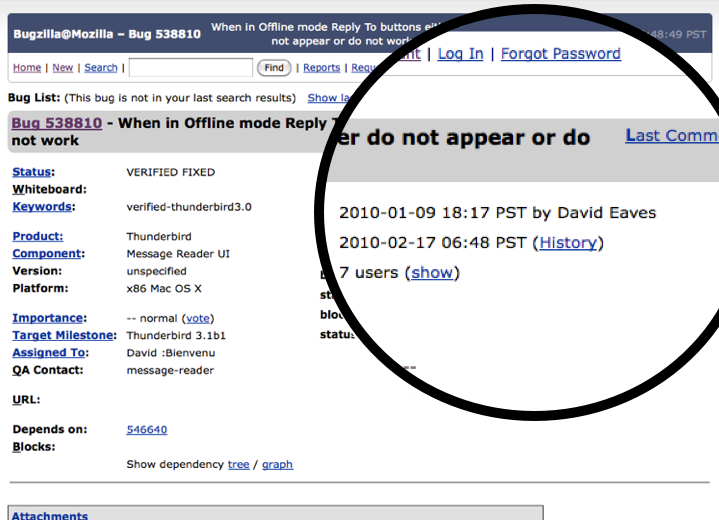
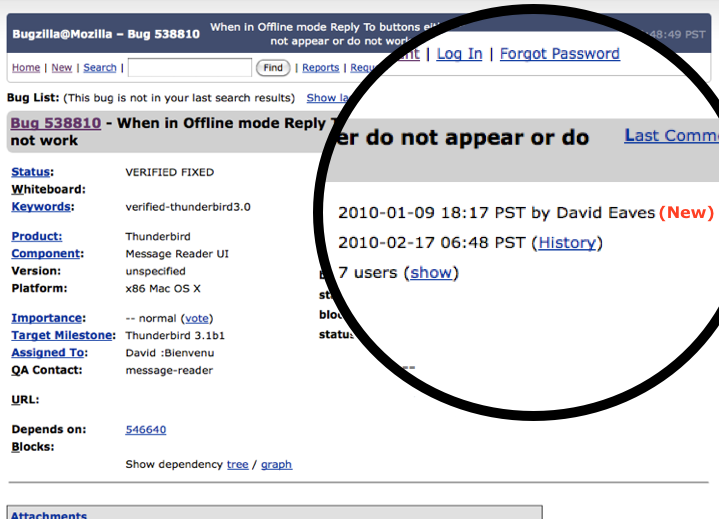
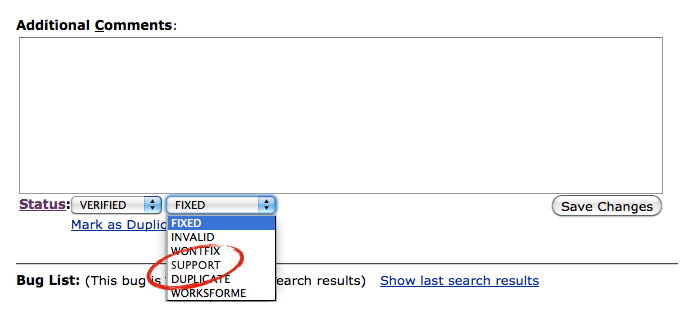
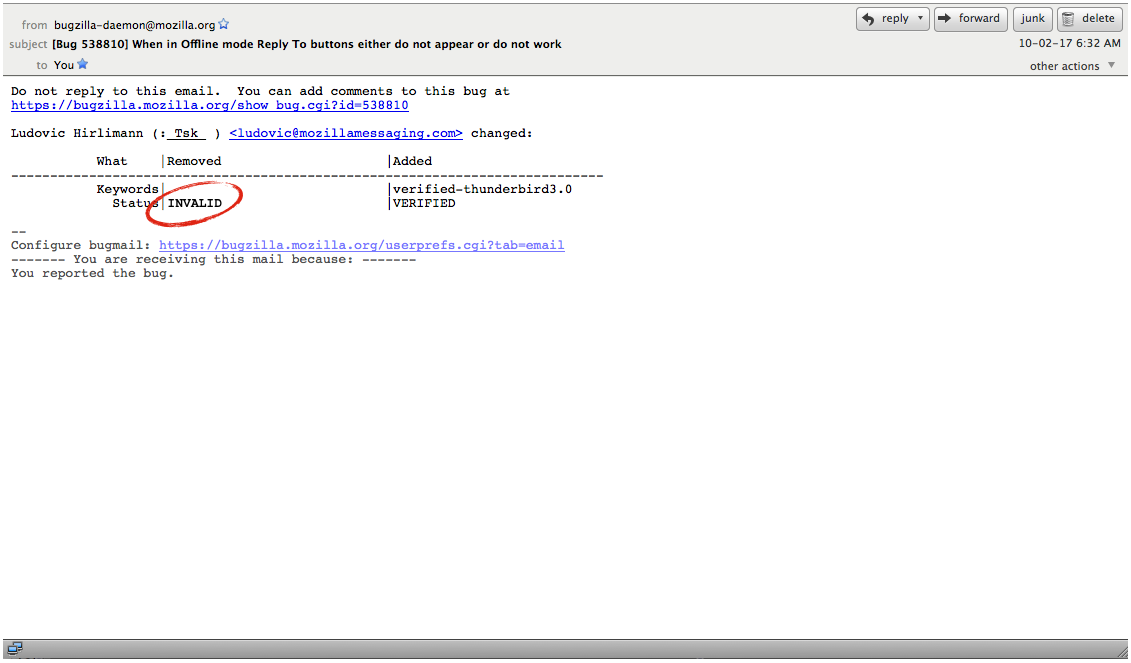
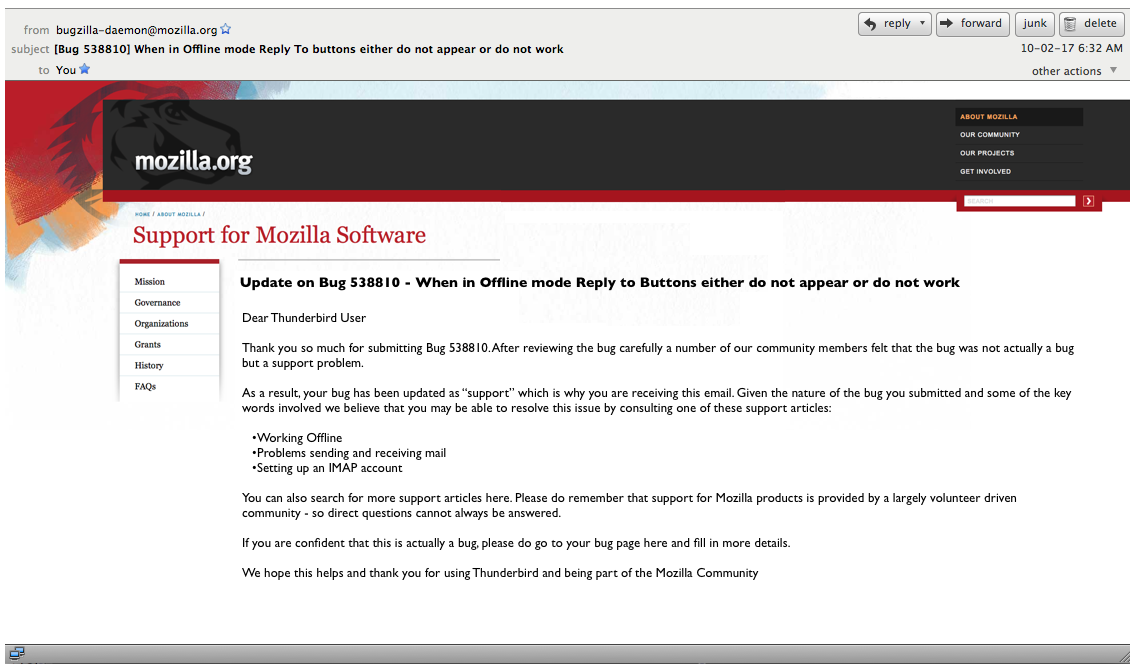
For those unfamiliar with Bugzilla it is an open source software application used by a number of projects to track “bugs” and feature requests in the software. So, for example, if you notice the software has a bug, you register it in Bugzilla, and then, if you are lucky and/or if the bug is really important, so intrepid developer will come along and develop a patch for it. Posted below, for example, is a bug I submitted for Thunderbird, an email client developed by Mozilla. It’s not as intuitive as it could be but you can get the general sense of things: when I submitted the bug (2010-01-09), who developed the patch (David Bienvenu), it’s current status (Fixed), etc…

Interestingly, an FOI or ATIP request really isn’t that different than a “bug” in a software program. In many ways, bugzilla is just a complex and collaborative “to do” list manager. I could imagine it wouldn’t be that hard to reskin it so that it could be used to manage and monitor access to information requests. Indeed, I suspect there might even be a community of volunteers who would be willing to work with the Office of the Information Commissioner to help make it happen.
Below I’ve done a mock up of what I think revamped Bugzilla, (renamed AccessZilla) might look like. I’m put numbers next to some of the features so that I can explain in detail about them below.
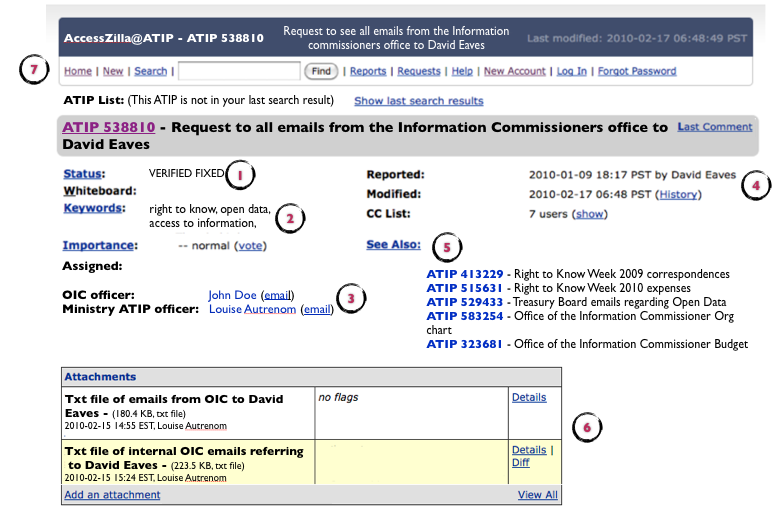
So what are some of the features I’ve included?
1. Status: Now an ATIP request can be marked with a status, these might be as simple as submitted, in process, under review, fixed and verified fixed (meaning the submitter has confirmed they’ve received it). This alone would allow the Information Commissioner, the submitter, and the public to track how long an individual request (or an aggregate of requests) stay in each part of the process.
2.Keywords: Wouldn’t it be nice to search of other FOR/ATIP requests with similar keywords? Perhaps someone has submitted a request for a document that is similar to your own, but not something you knew existed or had thought of… Keywords could be a powerful way to find government documents.
3. Individual accountability: Now you can see who is monitoring the request on behalf of the Office of the information commissioner and who is the ATIP officer within the Ministry. If the rules permitted then potential the public servants involved in the document might have their names attached here as well (or maybe this option will only be available to those who log on as ATIP officers.
4. Logs: You would be able to see the last time the request was modified. This might include getting the documents ready, expressing concern about privacy or confidentiality, or simply asking for clarification about the request.
5. Related requests: Like keywords, but more sophisticated. Why not have the software look at the words and people involved in the request and suggest other, completed requests, that it thinks might similar in type and therefor of interest to the user. Seems obvious.
6. Simple and reusable resolution: Once the ATIP officer has the documentation, they can simply upload it as an attachment to the request. This way not only can the original user quickly download the document, but anyone subsequent user who stumbles upon the request during a search could download the documents. Better still any public servant who has unclassified documents that might relate to the request can simply upload them directly as well.
7. Search: This feels pretty obvious… it would certainly make citizens life much easier and be the basic ante for any government that claims to be interested in transparency and accountability.
8. Visualizing it (not shown): The nice thing about all of these features is that the data coming out of them could be visualized. We could generate realt time charts showing average response time by ministry, list of respondees by speed from slowest to fastest, even something as mundane as most searched keywords. The point being that with visualizations is that a governments performance around transparency and accountability becomes more accessible to the general public.
It may be that there is much better software out there for doing this (like JIRA), I’m definitely open do suggestions. What I like about bugzilla is that it can be hosted, it’s free and its open source. Mostly however, software like this creates an opportunity for the Office of the Information Commissioner in Canada, and access to information managers around the world, to alter the incentives for governments to complete FOI/ATIP requests as well as make it easier for citizens to find out information about their government. It could be a fascinating project to reskin bugzilla (or some other software platform) to do this. Maybe even a Information Commissioners from around the world could pool their funds to sponsor such a reskinning of bugzilla…