For those who missed it over the weekend it turns out Canada ranks last in freedom of information study that looked at the world’s western Parliamentary democracies. What makes it all the more astounding is that a decade ago Canada was considered a leader.
Consider two from the Information Commissioner, Suzanne Legault quotes pulled from the piece:
Only about 16 per cent of the 35,000 requests filed last year resulted in the full disclosure of information, compared with 40 per cent a decade ago, she noted.
And delays in the release of records continue to grow, with just 56 per cent of requests completed in the legislated 30-day period last year, compared with almost 70 per cent at the start of the decade.
These are appalling numbers.
The sad thing is… don’t expect things to get better. Why?
Firstly, the current government seems completely uninterested in access to information, transparency and proactive disclosure, despite these being core planks of its election platform and core values of the reform movement that re-launched Canadian conservatism. Indeed, reforming and improving access to information is the only unfulfilled original campaign promise of the Conservatives – and there appears to be no interest in touching it. Quite the opposite – that political staff now intervene to block and restrict Access to Information Requests – contravening the legislation and policy – is now a well known and documented fact.
Second, this issue is of secondary importance to the public. While everyone will say they care about access to information and open government, then number of people (while growing) still remains small. These types of reports and issues are of secondary importance. This isn’t to say they don’t matter. They do – but generally after something bigger and nastier has come to light and the public begins to smell rot. Then studies like this become the type of thing that hurts a government – it gives legitimacy and language to a sentiment people widely feel.
Third, the public seems confused about who they distrust more – the fact is, however bad the current government is on this issue, the Liberal brand is still badly tarnished on this issue of transparent government due to the scandals from almost a decade ago. Sadly, this means that there will be less burden on this government to act since – every time the issue of transparency and open government arise – rather than act, Government leaders simply point out the other parties failings.
So as the world moves on while Canada remains stuck, its government becoming more opaque, distant and less accountable to the people that elect it.
Interestingly , this also has a real cost to Canada’s influence in the world. It means something when the world turns to you as an expert – as we once were on access to information – minister’s are consulted by other world leaders, your public servants are given access to information loops they might otherwise not know about, there is a general respect, a soft power, that comes from being an acknowledged leader. Today, this is gone.
Indeed, it is worth noting that of the countries survey in the above mentioned study, only Canada and Ireland do not have open data portals which allow for proactive disclosure.
It’s a sign of the times.
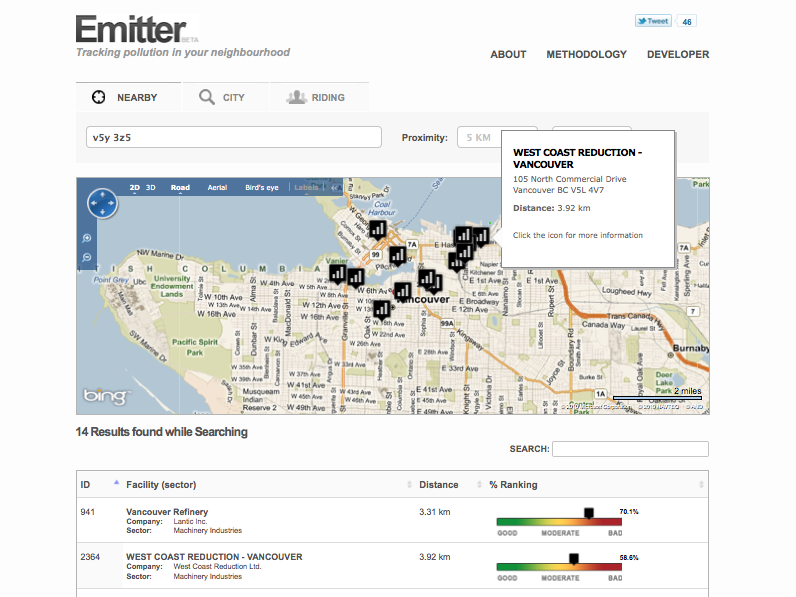

 In a month where our federal government cited imaginary data to justify policies on crime and has eliminated the gathering a huge swaths of effective data necessary for the efficient governing of our cities and rural communities as well as ensuring critical services will no longer reach innumerable Canadians, it is nice to see a province trying to do the opposite: not only understand that effective data is the cornerstone to good policy but to enable everyday, ordinary Canadians to leverage it so as to make smarter decisions, influence policy debates and empower themselves. It’s what a modern democracy, economy and civil society should look like.
In a month where our federal government cited imaginary data to justify policies on crime and has eliminated the gathering a huge swaths of effective data necessary for the efficient governing of our cities and rural communities as well as ensuring critical services will no longer reach innumerable Canadians, it is nice to see a province trying to do the opposite: not only understand that effective data is the cornerstone to good policy but to enable everyday, ordinary Canadians to leverage it so as to make smarter decisions, influence policy debates and empower themselves. It’s what a modern democracy, economy and civil society should look like.
