So it’s been a couple of weeks since Google+ launched and I’ll be honest, I’m really struggling with the service. I wanted to give it a few weeks before writing anything, which has been helpful in letting my thinking mature.
First, before my Google friends get upset, I want to acknowledge the reason I’m struggling has more to do with me than with Google+. My sense is that Google+ is designed to manage personal networks. In terms of social networking, the priority, like at Facebook, is on a soft version of the word “social” eg. making making the experience friendly and social, not necessarily efficient.
And I’m less interested in the personal experience than in the learning/professional/exchanging experience. Mark Jones, the global communities editor for Reuters, completely nailed what drives my social networking experience in a recent Economist special on the News Industry: “The audience isn’t on Twitter, but the news is on Twitter.” Exactly! That’s why I’m on Twitter. Cause that’s where the news is. It is where the thought leaders are interacting and engaging one another. Which is very different activity than socializing. And I want to be part of all that. Getting intellectually stimulated and engaged – and maybe even, occasionally, shaping ideas.
And that’s what threw me initially about Google+. Because of where I’m coming from, I (like many people) initially focused on sharing updates which begged comparing Google+ to Twitter, not Facebook. That was a mistake.
But if Google+ is about about being social above all else, it is going to be more like Facebook than Twitter. And therein lies the problem. As a directory, I love Facebook. It is great for finding people, checking up on their profile and seeing what they are up to. For some people it is good for socializing. But as a medium for sharing information… I hate Facebook. I so rarely use it, it’s hard to remember the last time I checked my stream intentionally.
So I’m willing to accept that part of the problem is me. But I’m sure I’m not alone so if you are like me, let me try to further breakdown why I (and maybe you too) are struggling.
Too much of the wrong information, too little of the right information.
The first problem with Google+ and Facebook is that they have both too much of the wrong information, and too little of the right information.
What do I mean by too much of the wrong? What I love about Twitter is its 140 character limit. Indeed, I’m terrified to read over at Mathew Ingram’s blog that some people are questioning this limit. I agree with Mathew: changing Twitter’s 140 character limit is a dumb idea. Why? For the same reason I thought it made sense back in March of 2009, before Google+ was even a thought:
What I love about Twitter is that it forces writers to be concise. Really concise. This in turn maximizes efficiency for readers. What is it Mark Twain said? “I didn’t have time to write a short letter, so I wrote a long one instead.” Rather than having one, or even thousands or readers read something that is excessively long, the lone drafter must take the time and energy to make it short. This saves lots of people time and energy. By saying what you’ve got to say in 140 characters, you may work more, but everybody saves.
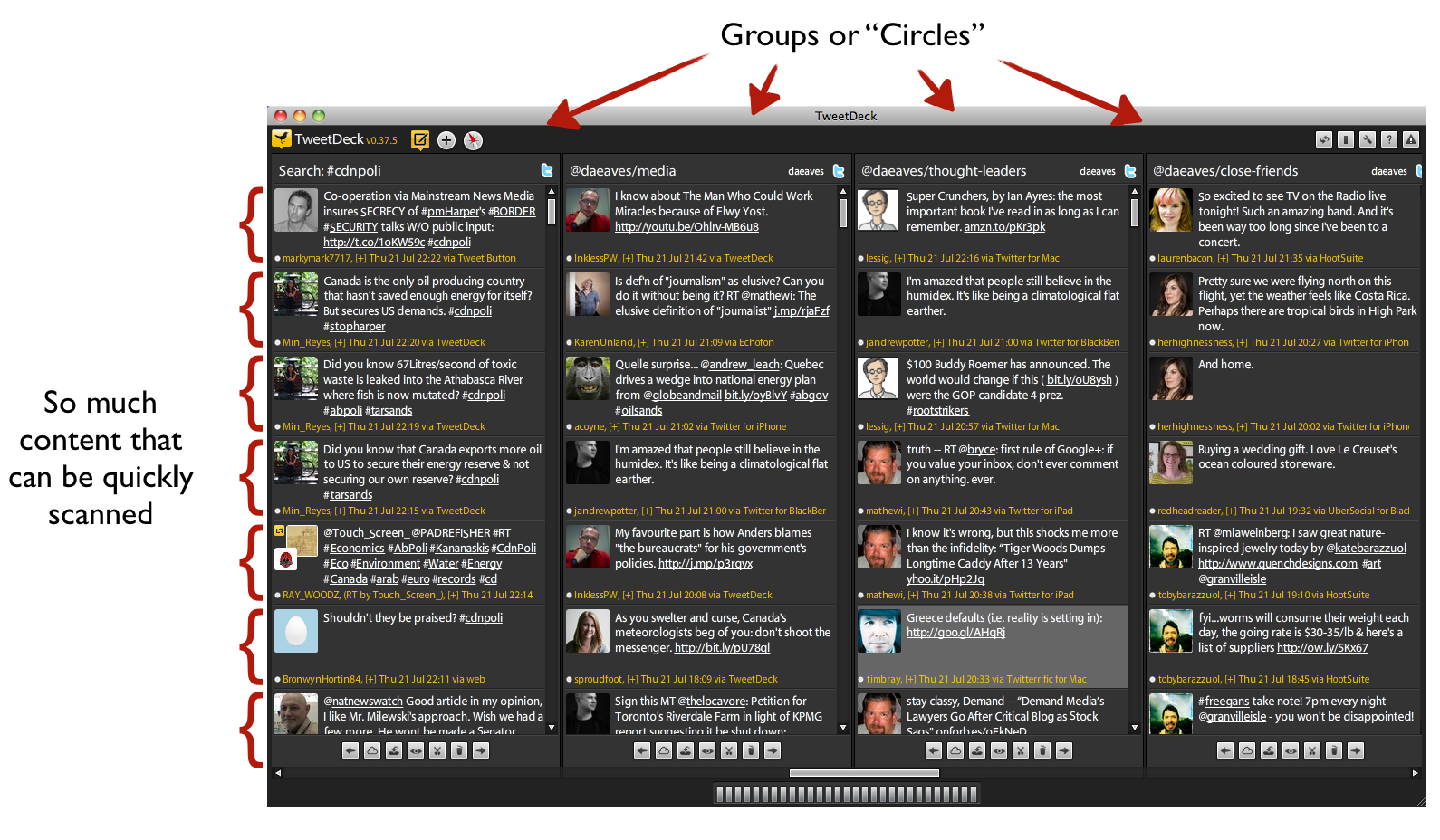
On the other hand, while I want a constraint over how much information each person can transmit, I want to be able to view my groups (or circles) of people as I please.
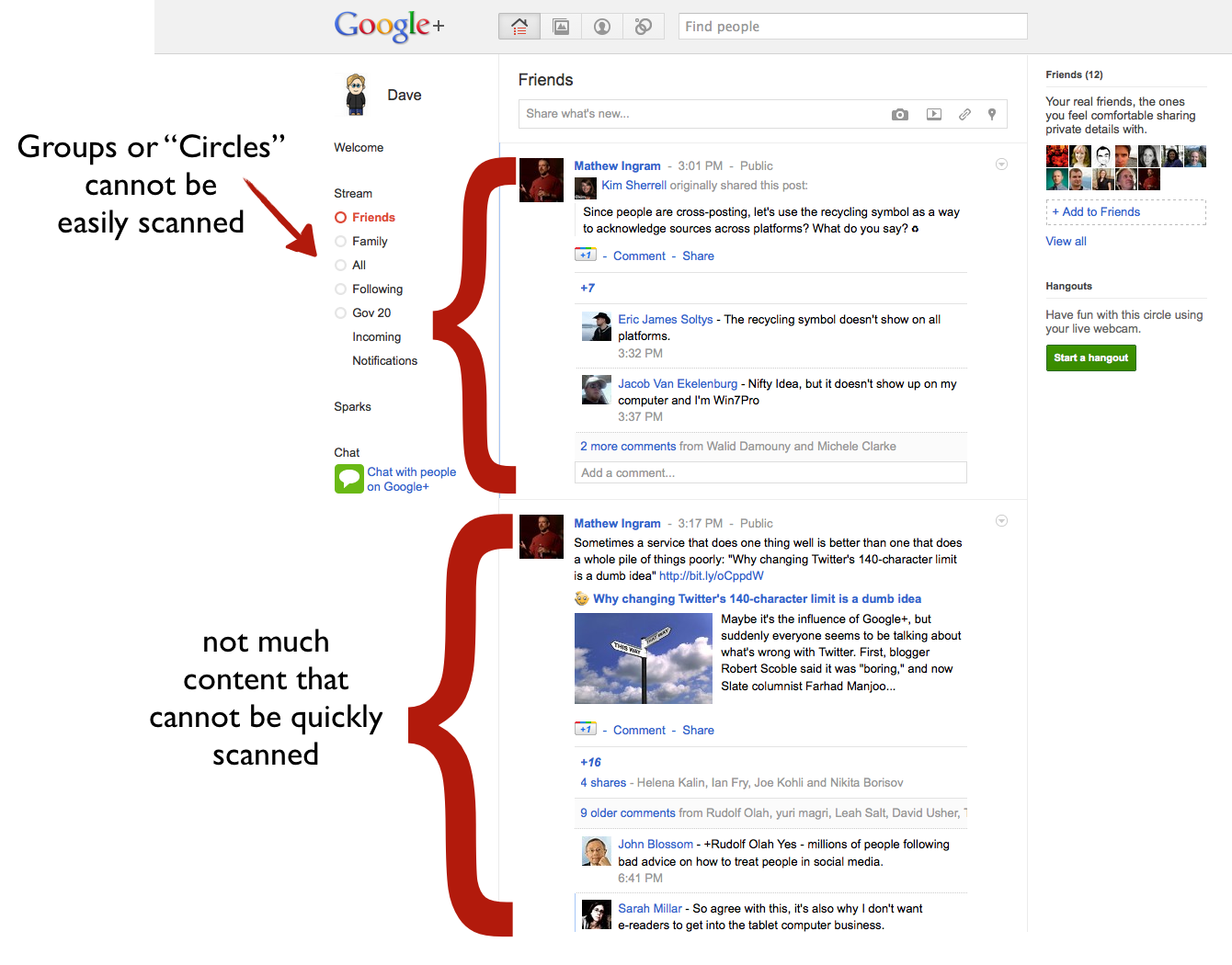
Consider the screen shot of TweetDeck below. Look how much information is being displayed in a coherent manner (of my choosing). It takes me maybe, maybe 30-60 seconds to scan all this. In one swoop I see what friends are up to, some of my favourite thought leaders, some columnists I respect… it is super fast and efficient. Even on my phone, switching between these columns is a breeze.

But now look at Google+. There are comments under each item…but I’m not sure I really care to see. Rather then the efficient stream of content I want, I essentially have a stream of content I didn’t ask for. Worse, I can see, what, maybe 2-5 items per screen, and of course I see multiple circles on a single screen.

Obviously, some of this is because Google+ doesn’t have any applications to display it in alternative forms. I find the Twitter homepage equally hard to use. So some of this could be fixed if (and hopefully when) Google makes public their Google+ API.
But it can’t solve some underlying problems. Because an item can be almost as long as the author wants, and there can be comments, Google+ doesn’t benefit from Twitter’s 140 character limit. As one friend put it, rather than looking at a stream of content, I’m looking at a blog in which everybody I know is a writer submitting content and in which an indefinite number of comments may appear. I’ll be honest: that’s not really a blog I’m interested in reading. Not because I don’t like the individual authors, but because it’s simply too much information, shared inefficiently.
Management Costs are too high
And herein lies the second problem. The management costs of Google+ are too high.
I get why “circles” can help solve some of the problems outlined above. But, as others have written, it creates a set of management costs that I really can’t be bothered with. Indeed this is the same reason Facebook is essentially broken for me.
One of the great things about Twitter is that it’s simple to manage: Follow or don’t follow. I love that I don’t need people’s permission to follow them. At the same time, I understand that this is ideal for managing divergent social groups. A lot of people live lives much more private than mine or want to be able to share just among distinct groups of small friends. When I want to do this, I go to email… that’s because the groups in my life are always shifting and it’s simple to just pick the email addresses. Managing circles and keeping track of them feels challenging for personal use. So Google+ ends up taking too much time to manage, which is, of course, also true of Facebook…
Using circles to manage for professional reasons makes way more sense. That is essentially what I’ve got with Twitter lists. The downside here is that re-creating these lists is a huge pain.
And now one unfair reason with some insight attached
Okay, so going to the Google+ website is a pain, and I’m sure it will be fixed. But presently my main Google account is centered around my eaves.ca address and Google+ won’t work with Google Apps accounts so I have to keep flipping to a gmail account I loathe using. That’s annoying but not a deal breaker. The bigger problem is my Google+ social network is now attached to an email account I don’t use. Worse, it isn’t clear I’ll ever be able to migrate it over.
My Google experience is Balkanizing and it doesn’t feel good.
Indeed, this hits on a larger theme: Early on, I often felt that one of the promises of Google was that it was going to give me more opportunities to tinker (like what Microsoft often offers in its products), but at the same time offer a seamless integrated operating environment (like what Apple, despite or because of their control freak evilness, does so well). But increasingly, I feel the things I use in Google are fractured and disconnected. It’s not the end of the world, but it feels less than what I was hoping for, or what the Google brand promise suggested. But then, this is what everybody says Larry Page is trying to fix.
And finally a bonus fair reason that’s got me ticked
Now I also have a reason for actively disliking Google+.
After scanning my address book and social network, it asked me if I wanted to add Tim O’Reilly to a circle. I follow Tim as a thought leader on Twitter so naturally I thought – let’s get his thoughts via Google+ as well. It turns out however, that Tim does not have a Google+ account. Later when I decided to post something a default settings I failed to notice sent emails to everyone in my circles without a Google+ account. So now I’m inadvertently spamming Tim O’Reilly who frankly, doesn’t need to get crap spam emails from me or anyone. I’m feeling bad for him cause I suspect, I’m not the only one doing it. He’s got 1.5 million followers on Twitter. That could be a lot of spam.
My fault? Definitely in part. But I think there’s a chunk of blame that can be heaped on to a crappy UI that wanted that outcome. In short: Uncool, and not really aligned with the Google brand promise.
In the end…
I remember initially, I didn’t get Twitter; after first trying it briefly I gave up for a few months. It was only after the second round that it grabbed me and I found the value. Today I’m struggling with Google+, but maybe in a few months, it will all crystallize for me.
What I get, is that it is an improvement on Facebook, which seems to becoming the new AOL – a sort of gardened off internet that is still connected but doesn’t really want you off in the wilds having fun. Does Google+ risk doing the same to Google? I don’t know. But at least circles are clearly a much better organizing system than anything Facebook has on offer (which I’ve really failed to get into). It’s far more flexible and easier to set up. But these features, and their benefits, are still not sufficient to overcome the cost setting it up and maintaining it…
Ultimately, if everybody moves, I’ll adapt, but I way prefer the simplicity of Twitter. If I had my druthers, I’d just post everything to Twitter and have it auto-post over to Google+ and/or Facebook as well.
But I don’t think that will happen. My guess is that for socially driven users (e.g. the majority of people) the network effects probably keep them at Facebook. And does Google+ have enough features to pull the more alpha type user away? I’m not sure. I’m not seeing it yet.
But I hope they try, as a little more competition in the social networking space might be good for everyone, especially when it comes to privacy and crazy end-user agreements.